Burp现在的爬虫有一系列严重的缺陷,特别是工作在使用了先进技术的web站点时。他的核心基于过时的web运作流程,现在已经不适用了。
爬虫模块维护了一个请求队列。该队列发送每个请求,然后在响应中寻找新的链接和表单,再将相关的请求添加到队列中。当网站后端的每个函数都有独一无二和稳定的url,使用了简单的基于cookie的session机制,每个相应返回确定的内容并且不包含服务端状态的时候,这种爬虫实现非常有效。但是大部分web应用已经不是这样运作的了。所以我们用一些更好的实现替换了当前的爬虫。
Burp的新爬虫使用了完全不同的模型。它会模拟真人使用浏览器的方式探测目标应用,通过点击链接和提交一些输入。他会构建一个目标应用各个功能(原文为locations )的定向图,展示了目标应用的各模块和其之间的联系:
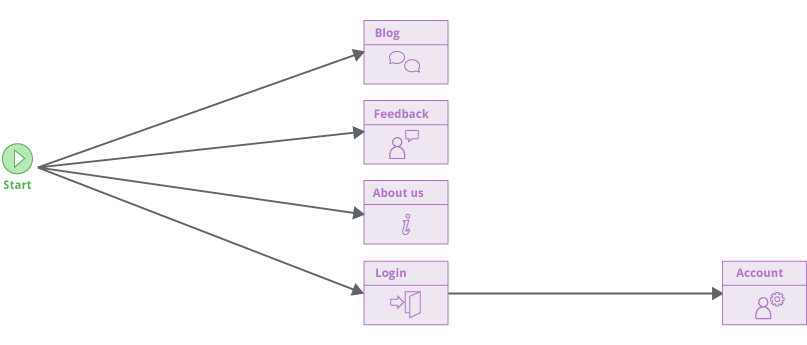
新的爬虫不会猜测目标url的结构。功能定义基于他们返回的内容,而不是连接他们的url。新的机制让爬虫在使用先进技术的网站上变得可靠,包括设置csrf token和cache-buster的url。甚至整个url都会随时变化的情况,爬虫也能构建精准的定向图:
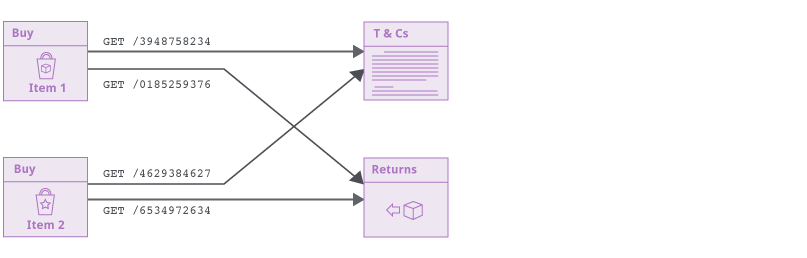
这个新的实现同样可以让新的爬虫处理一个url连接到不同的功能的情况,基于应用状态和用户的交互来实现:
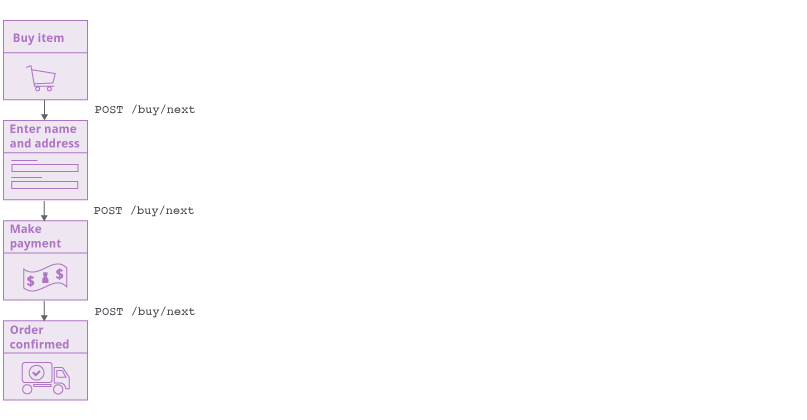
旧爬虫通过一个请求队列来跟踪它的工作状态。新的爬虫通过一个不同的方式。当爬虫逐渐覆盖目标应用的时候,它关注于定向图有哪些边缘部分没有完成。表现在这些应用内部的连接(或者是导航定向)被观察到但是并没有被访问。但是爬虫不会在脱离上下文的环境下直接访问这些url。而是在有指向这些url的页面进行访问。这几乎模拟了正常用户使用浏览器的状态。
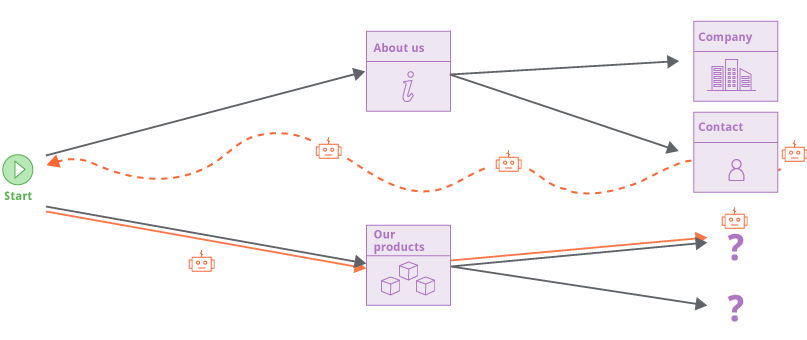
通过不猜测url结构来爬取网站在处理现代web应用时非常高效,但可能在观察大量响应内容时导致一个潜在问题。现代web站点经常包含大量的多余的导航url(页面footer burger menus等等),这意味着所有东西和其他东西都是直接相连的(包含大量重复url?)。新的爬虫使用一系列技术来解决这个问题:构建已经爬取的url的指纹来避免重复访问;使用广度优先算法爬取新的内容;可设置的爬取强度来限制爬虫。这些方法都可以正确的处理“无限的”应用,例如日历。
在之后的几天,我们会介绍新爬虫更强大的功能。