银行需要局域网,专线太贵,利用vpn和ipsec技术构建。银行是hub-spoke结构,点到多点的mgre,nhrp自动获取ip,建立动态隧道。shortcut,spoke只保存hub的路由。
l 数据机密性(Confidentiality):IPsec发送方在通过网络传输包前对包进行加密。
l 数据完整性(Data Integrity):IPsec接收方对发送方发送来的包进行认证,以确保数据在传输过程中没有被篡改。
l 数据来源认证(Data Authentication):IPsec在接收端可以认证发送IPsec报文的发送端是否合法。
l 防重放(Anti-Replay):IPsec接收方可检测并拒绝接收过时或重复的报文。
AH : 该协议主要是提供数据的认证服务和源验证服务,这个协议不提供加密功能,有效的抗重播能力
ESP:认证的头部来保证数据的完整性,同时可以对payload进行加密
IKE:密钥交换协议,主要是用于两端协商使用的加解密算法和SA信息
非对称加密:
RSA:
1:随机找两个质数 P 和 Q ,P 与 Q 越大,越安全。比如 P = 67 ,Q = 71。计算他们的乘积 n = P * Q = 4757 ,转化为二进为 1001010010101,该加密算法即为 13 位,实际算法是 1024 位 或 2048 位,位数越长,算法越难被破解。计算N=p*q;
2 φ(n) 表示在小于等于 n 的正整数之中,与 n 构成互质关系的数的个数。例如:在 1 到 8 之中,与 8 形成互质关系的是1、3、5、7,所以 φ(n) = 4 如果 n = P * Q,P 与 Q 均为质数,则 φ(n) = φ(P * Q)= φ(P - 1)φ(Q - 1) = (P - 1)(Q - 1) 。
3 选择一个小于r = φ(N) 并与r互质的整数e,求得e关于r的模反元素,命名为d,如果两个正整数a和n互质,那么一定可以找到整数b,使得 ab-1 被n整除,或者说ab被n除的余数是1。
4 此时我们的*(N , e)是公钥,(N, d)为私钥,爱丽丝会把公钥(N, e)传给鲍勃,然后将(N, d)*自己藏起来。一对公钥和私钥就产生了,鲍勃(明文)a^e % n = b(密文)加密,爱丽丝收到后就可以解密得到自己的信息了。
- 比如知道e和r,因为d是e关于r的模反元素;r是φ(N) 的值
- 而φ(N)=(p-1)(q-1),所以知道p和q我们就能得到d;
- N = pq,从公开的数据中我们只知道N和e,所以问题的关键就是对N做因式分解能不能得出p和q
DH:
设有这么一个二元组 (q, p) = (3, 7)
两个大数p和q并公开,其中p是一个素数,q是p的一个模p本原单位根(primitive root module p),所谓本原单位根就是指在模p乘法运算下,g的1次方,2次方……(p-1)次方这p-1个数互不相同,并且取遍1到p-1
(1)Alice 选择一个范围在[1, p-1]的随机数,为da= 5
(2)Alice 计算Pa = q^da mod p = 3^5 mod 7 = 5
(3)Bob选择一个范围在[1, p-1]的随机数,为db = 6
(4)Bob计算Pb = q^db mod p = 3^6 mod 7 = 1
(5)Alice和Bob交换Pa和Pb
(6)Alice计算共享密钥S = Pb ^da mod p = 1^5 mod 7 = 1
(7)Bob计算共享密钥S = Pa ^db mod p = 5^6 m 7 = 1
应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如域名系统DNS,支持万维网应用的 HTTP协议,支持电子邮件的 SMTP协议等等。
表示层,会话层
传输层:主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务。TCP UDP
网络层:在 计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送
数据链路层,物理层

TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态; TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。 TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号 seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。 TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。 当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。
三次握手主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用的是两次握手建立连接,假设有这样一种场景,客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。

客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。 服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。 客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。 服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。 客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗*∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。 服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
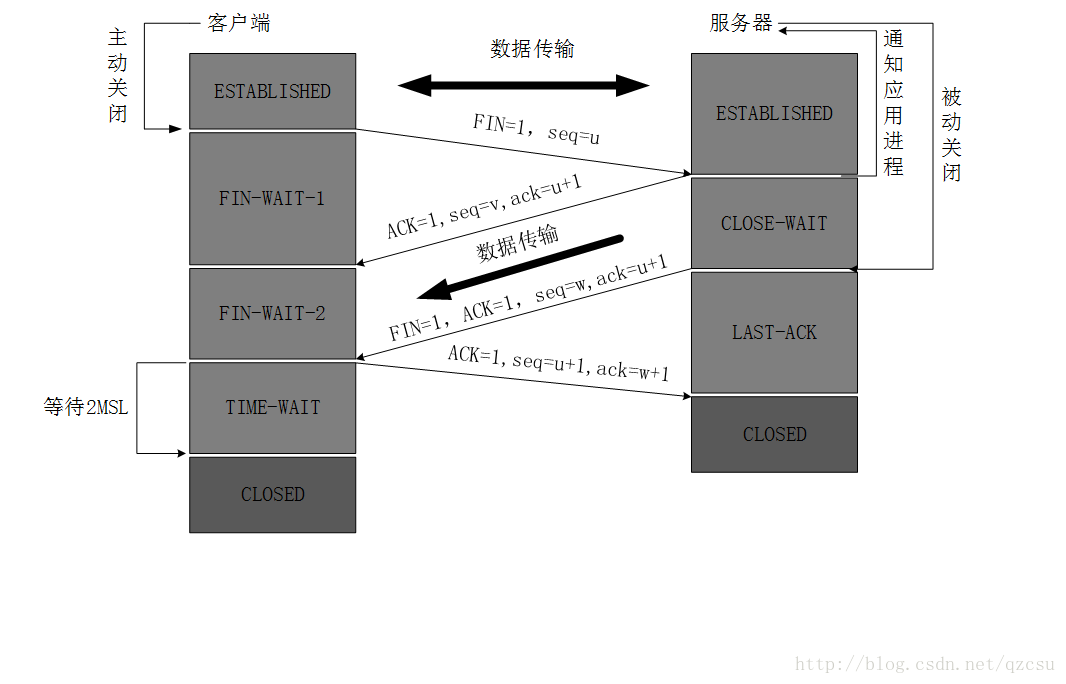
2MSL:
- 保证客户端发送的最后一个ACK报文段能够到达服务端。
这个ACK报文段有可能丢失,使得处于LAST-ACK状态的B收不到对已发送的FIN+ACK报文段的确认,服务端超时重传FIN+ACK报文段,而客户端能在2MSL时间内收到这个重传的FIN+ACK报文段,接着客户端重传一次确认,重新启动2MSL计时器,最后客户端和服务端都进入到CLOSED状态,若客户端在TIME-WAIT状态不等待一段时间,而是发送完ACK报文段后立即释放连接,则无法收到服务端重传的FIN+ACK报文段,所以不会再发送一次确认报文段,则服务端无法正常进入到CLOSED状态。
- 防止“已失效的连接请求报文段”出现在本连接中。
客户端在发送完最后一个ACK报文段后,再经过2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失,使下一个新的连接中不会出现这种旧的连接请求报文段。
- 面向连接。三次握手
- 应用数据被分割成 TCP 认为最适合发送的数据块。
- TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
- 校验和: TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
- TCP 的接收端会丢弃重复的数据。
- 流量控制: TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
- 拥塞控制: 当网络拥塞时,减少数据的发送。
- ARQ协议: 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
- 超时重传: 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
停止等待ARQ:
- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组;
- 在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认;
连续 ARQ 协议:可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了,又包括go-back-N 和 selective repeate
堵塞问题:
-
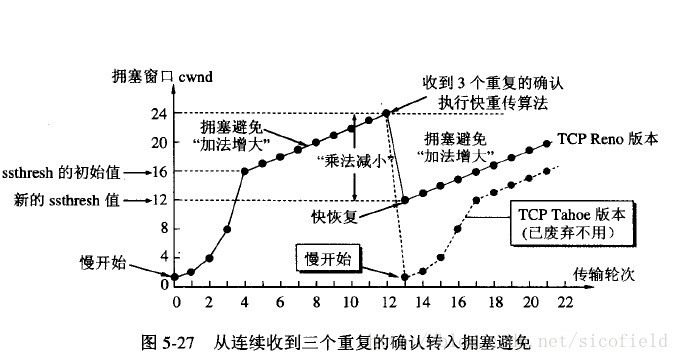
慢开始: 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd初始值为1,每经过一个传播轮次,cwnd加倍。
-
拥塞避免: 拥塞避免算法的思路是让拥塞窗口cwnd缓慢增大,即每经过一个往返时间RTT就把发送放的cwnd加1.
-
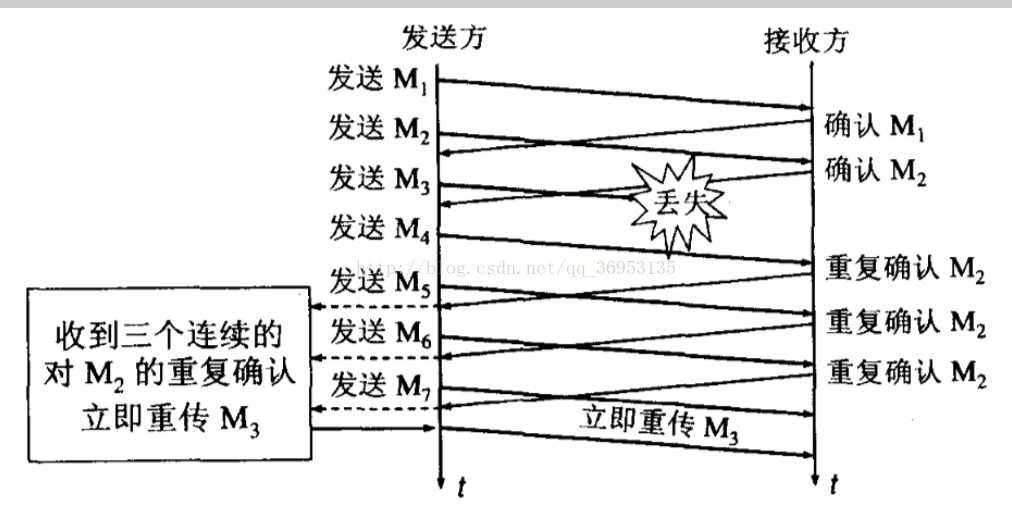
快重传与快恢复: 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。当发送方连续收到三个重复确认时,就执行“乘法减小”算法,*把慢开始门限减半*。这是为了预防网络发生拥塞,但不执行慢开始算法。把拥塞窗口的值设置为慢开始门限减半后的值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。

DDOS
除了大量发包的洪水攻击以外,NTP是标准的基于UDP协议传输的网络时间同步协议,由于UDP协议的无连接性,方便伪造源地址。攻击者使用特殊的数据包,也就是IP地址指向作为反射器的服务器,源IP地址被伪造成攻击目标的IP,反射器接收到数据包时就被骗了,会将响应数据发送给被攻击目标,耗尽目标网络的带宽资源。一般的NTP服务器都有很大的带宽,攻击者可能只需要1Mbps的上传带宽欺骗NTP服务器,就可给目标服务器带来几百上千Mbps的攻击流量。
SYN Flooding
攻击原理:
当 Server(B) 收到 Client(A) 的 SYN 请求报文时,将发送一个(ACK,SYN)应答报文,同时创建一个控制结构,将其加入到一个队列中,等待对方的 ACK 报文。接收到 ACK 报文后,双方都进入连接状态。如果 Server 在一段时间内没有收到应答消息,则控制块将被释放。
在 TCP 协议软件中,通常对每个端口等待建立链接的数目有一定限制,当队列长度到达设定阈值时,将丢弃后面到达的 TCP SYN 请求报文。
如果攻击者不断发送大量的 TCP SYN 报文,其他用户就无法再链接到被攻击者服务器。
应对措施:
通过增加连接数目、减小超时时间,可以缓解攻击,但是无法从根本阻止攻击,是 DOS 的一种,可通过 netstat 命令通过查看服务器网络连接情况,如果存在大量 SYN 的连接,则有可能收到了SYN Flooding攻击。
Land 攻击
利用了 TCP 连接建立的三次握手过程,通过向一个目标计算机发送一个 TCP SYN 报文(连接请求报文)而完成对目标计算机的攻击。
攻击原理:
与正常的 TCP SYN 报文不同的是,LAND 攻击报文的源 IP 地址和目的 IP 地址是相同的,都是目标计算机地址,这样目标计算机接受到 SYN 报文后,就会向该报文的源地址发送一个 ACK 报文,并建立一个 TCP 连接控制结构(TCB),而该报文的源地址就是自己,因此,这个 ACK 报文就发给了自己。这样如果攻击者发送了足够多的 SYN 报文,则目标计算机的 TCB 可能会耗尽,最终不能正常服务。
这也是一种 DOS 攻击。可以通过 Kali Linux 提供的如 hping3 实现伪造包的功能。
应对措施:
可以通过防火墙、路由设备,建立规则,丢掉源地址和目标地址相同的 SYN、SYN+ACK 和 TCP。
TCP 劫持
利用 TCP 会话劫持,可以方便地修改、伪造数据。
攻击原理:
TCP 通过三次握手建立连接以后,主要采用滑动窗口机制来验证对方发送的数据。如果对方发送的数据不在自己的接收窗口内,则丢弃此数据,这种发送序号不在对方接收窗口的状态称为非同步状态。
当通信双方进入非同步状态后,攻击者可以伪造发送序号在有效接收窗口内的报文,,也可以截获报文,篡改内容后,再修改发送序号,而接收方会认为数据是有效数据。
TCP 劫持的关键在于使通信双方进入非同步状态。有多种方法可以达到此目的。
如四次挥手状态图所示,在主机 A 发送 SYN 请求后,B 发送 ACK & SYN 进行应答,则 A 认为连接已经建立。此时,攻击者伪装成 A 向 B 发送一个 RST 报文(RST表示复位,用来异常的关闭连接),则 B 释放连接,攻击者继续伪装成 A 用自己的初始序列号和 B 建立新的连接,而 A 和 B 对此毫不觉察。当攻击者伪装成 A 和 B 建立连接后,A 和 B 就已经进入了非同步状态。
利用 Telnet 协议的 NOP 命令也可以使通信双方进入非同步状态。主机 B 接收到 NOP 命令后,并不进行任何操作,但确认序列号将会加 1。如果攻击者伪装成 A 向 B 发送大量的 NOP 命令,则会造成 A 和 B 的非同步状态。
应对措施:
检测 TCP 劫持的关键在于检测非同步状态。如果不断收到在接收窗口之外的数据或确认报文,则可以确定遭到 TCP 劫持攻击。或者设置禁止 RST 报文。
TCP 伪装
TCP 伪装主要是获取其他客户端的初始序列号进行伪装。
攻击原理:
要进行 TCP 伪装,就意味着在建立连接时,攻击者需要知道被伪装者的当前初始序列号。
序列号的生成算法一般有三种,一是不断增加一个常量,二是不断增加一个与时间相关的变量,三是伪随机数。对于前两种算法而言,其规律都能通过测试观察得到。也就是说,如果攻击者与被欺骗的目标主机处于同一网络,那么在排除了被伪装身份主机的干扰以后,可以比较简单地通过网络嗅探分析出初始序列号来。
当攻击者与可以通信的两台主机不在同一网络时,由于攻击者无法接收到响应包,这种攻击较为困难。但它并非万全,因为攻击者仍可配合路由欺骗的方法将响应包转发出来,从而实现上述攻击。
应对措施:
TCP 伪装利用 TCP 协议本身的设计,最自然、直接和本质的思路是不在有安全需求的场合使用 TCP,而是考虑 TLS 等对连接双方有认证、对网络会话有加密的协议。
也有一些其他的方法能够从外部防止该攻击:将序列号生成算法换为伪随机数能避免初始序列号被推解,或是在路由器拒绝来自外网但使用内网源 IP 地址的数据包。
应用层的CC攻击模拟多个正常用户不停地访问如论坛这些需要大量数据操作的页面,造成服务器资源的浪费。
因为TCP默认会使用Nagle算法,此算法会导致粘包问题。而Nagle算法主要做两件事,1)只有上一个分组得到确认,才会发送下一个分组;2)收集多个小分组,在一个确认到来时一起发送。多个分组拼装为一个数据段发送出去,如果没有好的边界处理,在解包的时候会发生粘包问题。另外多个进程使用一个TCP连接,此时多种不同结构的数据进到TCP的流式传输,边界分割肯定会出这样或者那样的问题。接收方不及时接收缓冲区的包,造成多个包接收。
1.Nagle算法问题导致的,需要结合应用场景适当关闭该算法,或者自己强行push出去每个数据包。
2.其他几种情况的处理方法主要分两种:
- 尾部标记序列。通过特殊标识符表示数据包的边界,例如\n\r,\t,或者一些隐藏字符。
- 头部标记分步接收。在TCP报文的头部加上表示数据长度。
- 应用层发送数据时定长发送。
TCP与UDP基本区别 1.基于连接与无连接 2.TCP要求系统资源较多,UDP较少; 3.UDP程序结构较简单 4.流模式(TCP)与数据报模式(UDP); 5.TCP保证数据正确性,UDP可能丢包 6.TCP保证数据顺序,UDP不保证
UDP应用场景: 1.面向数据报方式 2.网络数据大多为短消息 3.拥有大量Client 4.对数据安全性无特殊要求 5.网络负担非常重,但对响应速度要求高
具体编程时的区别 1.socket()的参数不同 2.UDP Server不需要调用listen和accept 3.UDP收发数据用sendto/recvfrom函数 4.TCP:地址信息在connect/accept时确定 5.UDP:在sendto/recvfrom函数中每次均 需指定地址信息 6.UDP:shutdown函数无效
TCP服务器:
1、创建一个socket,用函数socket(); 2、设置socket属性,用函数setsockopt(); * 可选 3、绑定IP地址、端口等信息到socket上,用函数bind(); 4、开启监听,用函数listen(); 5、接收客户端上来的连接,用函数accept(); 6、收发数据,用函数send()和recv(),或者read()和write(); 7、关闭网络连接; 8、关闭监听;
TCP编程的客户端一般步骤是: 1、创建一个socket,用函数socket(); 2、设置socket属性,用函数setsockopt();* 可选 3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选 4、设置要连接的对方的IP地址和端口等属性; 5、连接服务器,用函数connect(); 6、收发数据,用函数send()和recv(),或者read()和write(); 7、关闭网络连接;
UDP 包的大小就应该是 1500 - IP头(20) - UDP头(8) = 1472(BYTES) TCP 包的大小就应该是 1500 - IP头(20) - TCP头(20) = 1460 (BYTES)
我们在用Socket编程时, UDP协议要求包小于64K,TCP没有限定。不过鉴于Internet上的标准MTU值为576字节,所以建议在进行Internet的UDP编程时,最好将UDP的数据长度控制在548字节 (576-8-20)以内。
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个Session)。在 Cookie 中附加一个 Session ID 来方式来跟踪。
Cookie 数据保存在客户端(浏览器端)保存用户信息,Session 数据保存在服务器端保存用户状态。
- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
- URL(Uniform Resource Location) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
http1.1流水线方式是客户在收到HTTP的响应报文之前就能接着发送新的请求报文。与之相对应的非流水线方式是客户在收到前一个响应后才能发送下一个请求。
1 输入网址后,第一步是浏览器对用户输入的网址做初步的格式化检查,经过Chrome的一番补全操作,URL在Chrome这里已经变成了http://http://www.baidu.com/:80
2 查找本地hosts文件,用来保存域名以及域名对应的IP地址。如果有,就调用这个IP地址映射,解析完成。
3 如果没有,则查找本地DNS解析器缓存是否有这个网址的映射,如果有,返回映射,解析完成。
4 如果没有,则查找填写或分配的首选DNS服务器,称为本地DNS服务器。服务器接收到查询时:
- 如果要查询的域名包含在本地配置区域资源中,返回解析结果,查询结束,此解析具有权威性。
- 如果要查询的域名不由本地DNS服务器区域解析,但服务器缓存了此网址的映射关系,返回解析结果,查询结束,此解析不具有权威性。
5 如果本地DNS服务器也失效:
如果未采用转发模式(迭代),本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后,会判断这个域名(如.com)是谁来授权管理,并返回一个负责该顶级域名服务器的IP,本地DNS服务器收到顶级域名服务器IP信息后,继续向该顶级域名服务器IP发送请求,该服务器如果无法解析,则会找到负责这个域名的下一级DNS服务器(如http://baidu.com)的IP给本地DNS服务器,循环往复直至查询到映射,将解析结果返回本地DNS服务器,再由本地DNS服务器返回解析结果,查询完成。
如果采用转发模式(递归),则此DNS服务器就会把请求转发至上一级DNS服务器,如果上一级DNS服务器不能解析,则继续向上请求。最终将解析结果依次返回本地DNS服务器,本地DNS服务器再返回给客户机,查询完成。
6 HTTP通信机制是在一次完整的HTTP通信过程中,Web浏览器与Web服务器之间将完成下列7个步骤:
- 建立TCP连接
在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建 Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则, 只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。
- Web浏览器向Web服务器发送请求行
一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令。例如:GET /sample/hello.jsp HTTP/1.1。
- Web浏览器发送请求头
- 浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。
- Web服务器应答
- 客户机向服务器发出请求后,服务器会客户机回送应答, HTTP/1.1 200 OK ,应答的第一部分是协议的版本号和应答状态码。
- Web服务器发送应答头
- 正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。
- Web服务器向浏览器发送数据
- Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据。
- Web服务器关闭TCP连接
- 一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码:
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
建立TCP连接->发送请求行->发送请求头->(到达服务器)发送状态行->发送响应头->发送响应数据->断TCP连接
- HTTP 的URL 以http:// 开头,而HTTPS 的URL 以https:// 开头
- HTTP 是不安全的,而 HTTPS 是安全的
- HTTP 标准端口是80 ,而 HTTPS 的标准端口是443
- 在OSI 网络模型中,HTTP工作于应用层,而HTTPS 的安全传输机制工作在传输层
- HTTP 无法加密,而HTTPS 对传输的数据进行加密
- HTTP无需证书,而HTTPS 需要CA机构颁发的SSL证书
使用 SSL 的 HTTPS 后,则会先演变为和 SSL 进行通信,然后再由 SSL (TLS) 和 TCP 进行通信。也就是说,HTTPS 就是身披了一层 SSL 的 HTTP。
TLS 用于两个通信应用程序之间提供保密性和数据完整性。TLS 由记录协议、握手协议、警告协议、变更密码规范协议、扩展协议等几个子协议组成,综合使用了对称加密、非对称加密、身份认证(还有哈希算法保证完整性)等
数字证书的申请人将生成由私钥和公钥以及证书签名请求(CSR)组成的密钥对。CSR是一个编码的文本文件,其中包含公钥和其他将包含在证书中的信息(例如域名,组织,电子邮件地址等)。密钥对和 CSR生成通常在将要安装证书的服务器上完成,并且 CSR 中包含的信息类型取决于证书的验证级别。与公钥不同,申请人的私钥是安全的,永远不要向 CA(或其他任何人)展示。
生成 CSR 后,申请人将其发送给 CA,CA 会验证其包含的信息是否正确,如果正确,则使用颁发的私钥对证书进行数字签名,然后将其发送给申请人。
| 应答头 | 说明 |
|---|---|
| Allow | 服务器支持哪些请求方法(如GET、POST等)。 |
| Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
| Content-Length | 表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。 |
| Content-Type | 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。 |
| Date | 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 |
| Expires | 应该在什么时候认为文档已经过期,从而不再缓存它? |
| Last-Modified | 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。 |
| Location | 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
| Refresh | 表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。 注意这种功能通常是通过设置HTML页面HEAD区的<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。 注意Refresh的意义是"N秒之后刷新本页面或访问指定页面",而不是"每隔N秒刷新本页面或访问指定页面"。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是<META HTTP-EQUIV="Refresh" ...>。 注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。 |
| Server | 服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。 |
| Set-Cookie | 设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。 |
| WWW-Authenticate | 客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。 注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问(例如.htaccess)。 |
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
要理解RESTful架构,最好的方法就是去理解Representational State Transfer这个词组到底是什么意思。
REST的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"。
**所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。**它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,**如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。**具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
- GET 用于获取信息,是无副作用的,是幂等的,且可缓存
- POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存
副作用指当你发送完一个请求以后,网站上的资源状态没有发生修改,即认为这个请求是无副作用的。比如注册用户这个请求是有副作用的,获取用户详情可以认为是无副作用的。
再引入一个幂等性的概念,幂等是说,一个请求原封不动的发送N次和M次(N不等于M,N和M都大于1)服务器上资源的状态最终是一致的。比如发贴是非幂等的,重放10次发贴请求会创建10个帖子。但修改帖子内容是幂等的,一个修改请求重放无论多少次,帖子最终状态都是一致的。
GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存,(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了
为了安全考虑,给予了两者不同的权限,申请外部资源如内存条,网卡等时从用户态到内核态:
- 系统调用,这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如前例中fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。如在读写文件,read write时,或者申请堆内存:
进程:exit, fork
文件:chmod,改变文件权限
设备:如open read等,
信息:如getcpu
通信:如管道,mmap
- 异常:如果当前进程运行在用户态,如果这个时候发生了异常事件,就会触发切换。例如:缺页异常。如果虚拟地址对应物理地址不在物理内存中,则产生缺页中断,真正分配物理地址,同时更新进程的页表;如果此时物理内存已耗尽,则根据内存替换算法淘汰部分页面至物理磁盘中。
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作: **1、**检查要访问的虚拟地址是否合法 **2、**查找/分配一个物理页 **3、*填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)* 4、**建立映射关系(虚拟地址到物理地址)
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
- 外设中断:当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
通常,中断响应时硬件已经保存了PC和PS的内容,但是还有一些状态环境信息需要保存起来。
如果不做保存处理,那麽即使以后能按断点地址返回到被中断程序,但由于环境被破坏,原程序也无法正确运行。
中断响应时硬件处理时间很短,所以保存现场工作可由软件来协助硬件完成,并且在进入中断处理程序时就立即去做。
对现场信息的保存方式是多样化的,常用方式有两种:
一种是集中式保存:在内存的系统区中设置一个中断现场保存栈,所有中断的现场信息都统一保存在这个栈中, 进栈和退栈操作由系统严格按照后进先出原则实施;
另一种是分散式保存:就是在每个进程的PCB中设置一个核心栈,一旦程序被中断,它的中断现场信息就保存在自己的核心栈中。
进程是系统进行资源调度和分配的基本单位;线程是CPU调度的基本单位。
进程 = 资源 (包括寄存器值,PCB,内存映射表)+ TCB(栈结构) 线程 = TCB(栈结构)
线程 的资源是共享的 进程 间的资源是分隔独立的,内存映射表不同,占用物理内存地址是分隔的
线程 的切换只是切换PC,切换了TCB(栈结构) 进程 的切换不仅要切换PC,还包括切换资源,即切换内存映射表
多线程之所以主要与IO有关,比如cpu读取磁盘文件,会下发命令给DMA,DMA指挥磁盘把文件放入内存,放入后告诉CPU让它读取内存,这个过程中一个线程在等待文件读取时便可切换至其他的线程
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
- 使用全局变量,主要由于多个线程可能更改全局变量.
- 每一个线程都可以拥有自己的消息队列(UI线程默认自带消息队列和消息循环,工作线程需要手动实现消息循环),因此可以采用消息进行线程间通信sendMessage,postMessage。
- 临界区对应着一个CcriticalSection对象,当线程需要访问保护数据时,调用EnterCriticalSection函数;当对保护数据的操作完成之后,调用LeaveCriticalSection函数释放对临界区对象的拥有权,以使另一个线程可以夺取临界区对象并访问受保护的数据。
- 互斥量:采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。
- 信号量:它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 事件(信号):通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。则允许一个线程在处理完一个任务后,主动唤醒另外一个线程执行任务
匿名管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
高级管道:将另一个程序当做一个新的进程在当前程序进程中启动,则它算是当前程序的子进程,这种方式我们成为高级管道方式,半双工。
有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。它是一种文件类型。
消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。利用ip地址+协议+端口号唯一标示网络中的一个进程。
服务器根据地址类型(ipv4,ipv6)、socket类型、协议创建socket
服务器为socket绑定ip地址和端口号
服务器socket监听端口号请求,随时准备接收客户端发来的连接,这时候服务器的socket并没有被打开
客户端创建socket
客户端打开socket,根据服务器ip地址和端口号试图连接服务器socket
服务器socket接收到客户端socket请求,被动打开,开始接收客户端请求,直到客户端返回连接信息。这时候socket进入阻塞状态,所谓阻塞即accept()方法一直到客户端返回连接信息后才返回,开始接收下一个客户端连接请求
客户端连接成功,向服务器发送连接状态信息
服务器accept方法返回,连接成功
客户端向socket写入信息
服务器读取信息
客户端关闭
服务器端关闭
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的
调用select函数时到底发生了什么,即如何实现同时监听多个socket的。假设我们需要监听的读套接字read[],它作为参数传递进了select函数。
select(fd_set read[],fd_set [],fd_set [],timeout)从用户空间拷贝fd_set到内核空间,也即从当前程序拷贝fd_set数组进内核,fd_set是保存了连接的文件描述符,简单的说,是可以对socket进行操作的long型数组。
使用copy_from_user从用户空间拷贝fd_set到内核空间,
注册回调函数__pollwait,__pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。
遍历所有fd,调用其对应的poll方法,poll方法返回时会返回一个描述读写操作是否就绪的1024位mask掩码,根据这个mask掩码给fd_set赋值。这个mask或者叫bitmap在每次循环(监听需要无限循环)都需要初始化。如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
把fd_set从内核空间拷贝到用户空间。
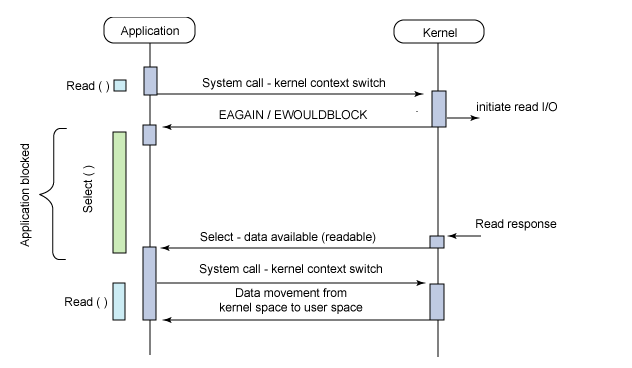
select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024,并且需要初始化。
poll使用了poll使用pollfd结构,传入了这个数组:其中events表示读写,revents被置位表示该fd有消息传来,其他和select差不多
epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd。这个就绪列表只包含有消息的fd, 并且epoll_wait返回就绪的个数,这样就不需要全部遍历。
调用epoll_create时,做了以下事情:
- 内核帮我们在epoll文件系统里建了个file结点;
- 在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket;
- 建立一个list链表,用于存储准备就绪的事件。
调用epoll_ctl时,做了以下事情:
- 把socket放到epoll文件系统里file对象对应的红黑树上;
- 给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里
调用epoll_wait时,做了以下事情: 观察list链表里有没有数据。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已。
PCB(Process Control Block):用来记录进程信息的数据结构(管理进程的核心,包含了PID等进程的所有关键信息)
队列:就绪队列、等待(阻塞)队列。
运行态:进程占用CPU,并在CPU上运行; 就绪态:进程已经具备运行条件,但是CPU还没有分配过来; 阻塞态:进程因等待某件事发生而暂时不能运行;
运行——>就绪:1,主要是进程占用CPU的时间过长,而系统分配给该进程占用CPU的时间是有限的;
2,在采用抢先式优先级调度算法的系统中,当有更高优先级的进程要运行时该进程就被迫让出CPU,该进程便由执行状态转变为就绪状态。
就绪——>运行:运行的进程的时间片用完,调度就转到就绪队列中选择合适的进程分配CPU
运行——>阻塞:正在执行的进程因发生某等待事件而无法执行,则进程由执行状态变为阻塞状态,如发生了I/O请求
阻塞——>就绪:进程所等待的事件已经发生,就进入就绪队列
简单分为连续分配管理方式和非连续分配管理方式这两种。连续分配管理方式是指为一个用户程序分配一个连续的内存空间,常见的如 块式管理 。同样地,非连续分配管理方式允许一个程序使用的内存分布在离散或者说不相邻的内存中,常见的如页式管理 和 段式管理。
- 块式管理 : 远古时代的计算机操系统的内存管理方式。将内存分为几个固定大小的块,每个块中只包含一个进程。如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,我们称之为碎片。
- 页式管理 :把主存分为大小相等且固定的一页一页的形式,页较小,相对相比于块式管理的划分力度更大,提高了内存利用率,减少了碎片。页式管理通过页表对应逻辑地址和物理地址。
- 段式管理 : 页式管理虽然提高了内存利用率,但是页式管理其中的页实际并无任何实际意义。 段式管理把主存分为一段段的,每一段的空间又要比一页的空间小很多 。但是,最重要的是段是有实际意义的,每个段定义了一组逻辑信息,例如,有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。 段式管理通过段表对应逻辑地址和物理地址。
- 段页式管理机制结合了段式管理和页式管理的优点。简单来说段页式管理机制就是把主存先分成若干段,每个段又分成若干页,也就是说 段页式管理机制 中段与段之间以及段的内部的都是离散的。
页表管理机制中有两个很重要的概念:快表和多级页表,这两个东西分别解决了页表管理中很重要的两个问题。你给我简单介绍一下吧!
🙋 我 :在分页内存管理中,很重要的两点是:
- 虚拟地址到物理地址的转换要快。
- 解决虚拟地址空间大,页表也会很大的问题。
快表
为了解决虚拟地址到物理地址的转换速度,操作系统在 页表方案 基础之上引入了 快表 来加速虚拟地址到物理地址的转换。我们可以把块表理解为一种特殊的高速缓冲存储器(Cache),其中的内容是页表的一部分或者全部内容。作为页表的 Cache,它的作用与页表相似,但是提高了访问速率。由于采用页表做地址转换,读写内存数据时 CPU 要访问两次主存。有了快表,有时只要访问一次高速缓冲存储器,一次主存,这样可加速查找并提高指令执行速度。
使用快表之后的地址转换流程是这样的:
- 根据虚拟地址中的页号查快表;
- 如果该页在快表中,直接从快表中读取相应的物理地址;
- 如果该页不在快表中,就访问内存中的页表,再从页表中得到物理地址,同时将页表中的该映射表项添加到快表中;
- 当快表填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
看完了之后你会发现快表和我们平时经常在我们开发的系统使用的缓存(比如 Redis)很像,的确是这样的,操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。
多级页表
引入多级页表的主要目的是为了避免把全部页表一直放在内存中占用过多空间,特别是那些根本就不需要的页表就不需要保留在内存中。多级页表属于时间换空间的典型场景
内存的分段和分页管理方式和由此衍生的一堆段页式等都属于内存的不连续分配。什么叫不连续分配?就是把程序分割成一块一块的装入内存,在物理上不用彼此相连,在逻辑上使用段表或者页表将离散分布的这些小块串起来形成逻辑上连续的程序。在基本的分页概念中,我们把程序分成等长的小块。这些小块叫做“页(Page)”,同样内存也被我们分成了和页面同样大小的”**页框(Frame)“,**一个页可以装到一个页框里。在执行程序的时候我们根据一个页表去查找某个页面在内存的某个页框中,由此完成了逻辑到物理的映射
分页由系统完成,分段有时在编译过程中会指定划分,因此可以保留部分逻辑特征,容易实现分段共享。
分段:逻辑地址-》线性地址(虚拟地址)
分页:虚拟地址-》物理地址
分段和分页其实都是一种对地址的划分或者映射的方式。
两者的区别主要有以下几点:
a)页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率;或者说,分页仅仅是由于系统管理的需要,而不是用户的需要(也是对用户透明的)。段是信息的逻辑单位,它含有一组其意义相对完整的信息(比如数据段、代码段和堆栈段等)。分段的目的是为了能更好的满足用户的需要(用户也是可以使用的)。
b)页的大小固定且由系统确定,把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而一个系统只能有一种大小的页面。段的长度却不固定,决定于用户所编写的程序,通常由编辑程序在对源程序进行编辑时,根据信息的性质来划分。
c)分页的作业地址空间是一维的,即单一的线性空间,程序员只须利用一个记忆符(线性地址的16进制表示),即可表示一地址。分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名(比如数据段、代码段和堆栈段等),又需给出段内地址。
d)页和段都有存储保护机制。但存取权限不同:段有读、写和执行三种权限;而页只有读和写两种权限。
- 共同点
- 分页机制和分段机制都是为了提高内存利用率,较少内存碎片。
- 页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。
- 区别
- 页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。
- 分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入就绪队列。在进程调度中采用FCFS算法时,则每次调度是从就绪队列中选择一个最先进入该队列的进程,为之分配处理机,使之投入运行。该进程一直运行到完成或发生某事件而阻塞后才放弃处理机。
短作业(进程)优先调度算法,是指对短作业或短进程优先调度的算法。它们可以分别用于作业调度和进程调度。短作业优先(SJF)的调度算法是从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。而短进程优先(SPF)调度算法则是从就绪队列中选出一个估计运行时间最短的进程,将处理机分配给它,使它立即执行并一直执行到完成,或发生某事件而被阻塞放弃处理机时再重新调度。
在早期的时间片轮转法中,系统将所有的就绪进程按先来先服务的原则排成一个队列,每次调度时,把CPU分配给队首进程,并令其执行一个时间片。时间片的大小从几ms到几百ms。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾;然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证就绪队列中的所有进程在一给定的时间内均能获得一时间片的处理机执行时间。换言之,系统能在给定的时间内响应所有用户的请求。
**多级反馈队列调度算法:**目前公认较好的调度算法;设置多个就绪队列并为每个队列设置不同的优先级,第一个队列优先级最高,其余依次递减。优先级越高的队列分配的时间片越短,进程到达之后按FCFS放入第一个队列,如果调度执行后没有完成,那么放到第二个队列尾部等待调度,如果第二次调度仍然没有完成,放入第三队列尾部…。只有当前一个队列为空的时候才会去调度下一个队列的进程。
现代操作系统了提供了一种对主存的抽象概念,叫做虚拟内存。它为每个进程提供了一个非常大的,一致的和私有的地址空间。虚拟内存提供了以下的三个关键能力:
- 它将主存看成是一个存储在磁盘空间上的地址空间的高速缓存,主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据。
- 它为内阁进程提供了一致的地址空间,简化了内存管理。
- 它保护了每个进程的地址空间不被其他进程破坏。
计算机的主存可以看做是一个由 M 个连续的字节大小的单元组成的数组。每个字节都有一个唯一的物理地址(Physical Address,PA)。第一个字节的地址为 0,接下来的地址为 1,以此类推。CPU 访问内存的最简单的方式是使用物理寻址(physical addressing)。现在处理器采用的是一个程序虚拟寻址(virtual addressing)的寻址方式,CPU 通过生成一个虚拟地址(virtual address,VA)来访问主存,这个虚拟地址在被送到主存之前会先转换成一个物理地址。将虚拟地址转换成物理地址的任务叫做地址翻译(address translation),地址翻译需要 CPU 硬件和操作系统之间的配合。 CPU 芯片上叫做内存管理单元(Menory Management Unit, MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。
在一个带虚拟内存的系统中,CPU 从一个有 N= 2^n 个地址的地址空间中生成虚拟地址,这个地址空间就称为虚拟地址空间.
从概念上来说,虚拟内存被组织成为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组,也就是字节数组。每个字节都有一个唯一的虚拟地址作为数组的索引。磁盘上活动的数组内容被缓存在主存中。在存储器结构中,较低层次上的磁盘的数据被分割成块,这些块作为和较高层次的主存之间的传输单元。主存作为虚拟内存的缓存。
虚拟内存(VM)系统将虚拟内存分割成称为虚拟页(Virtual Page,VP)的大小固定的块,每个虚拟页的大小为 P = 2 的 p 次方 字节。同样的,物理内存被分割为物理页(Physical Page,PP),大小也为 P 字节(物理页也称作页帧(page frame))。
在任意时刻,虚拟页面的集合都分为三个不相交的子集:
- 未分配的,VM 系统还未分配(或者创建)的页,未分配的页没有任何数据和它们关联,因此不占用任何内存空间。
- 缓存的,当前已缓存在物理内存中的已分配页。
- 未缓存的,未缓存在物理内存中的已分配页


我们使用 SRAM 缓存来表示位于 CPU 和 主存之间的 L1, L2 和 L3 高速缓存,使用 DRAM 缓存来表示虚拟内存系统中的缓存,也就是主存。
在存储器层次结构中, DRAM 比 SRAM 慢个大约 10x 倍,磁盘比 DRAM 慢大约 10, 000x 倍。因此 DRAM 缓存的不命中比 SRAM 缓存中的不命中要昂贵的多,因为 DRAM 缓存不命中需要和磁盘传送数据,而 SRAM 缓存不命中是和 DRAM 传送数据。
归根到底, DRAM 缓存的组织结构是由巨大的不命中开销驱动的。同任何缓存一样,虚拟内存系统必须有某种方法来判定一个虚拟也是否缓存在 DRAM 的某个地方。如果命中缓存,那么虚拟内存系统还必须确认这个虚拟页存在哪个物理页中。如果没有命中缓存,那么虚拟内存系统必须判断虚拟页存放在磁盘的哪个位置,在物理内存中选择一个牺牲页,并将虚拟页从磁盘复制到 DRAM,替换这个牺牲页。
这些功能由软硬件联合提供,包括操作系统软件,MMU 中的地址翻译硬件和一个存放在物理内存中叫页表(page table)的数据结构,页表将虚拟页映射到物理页。每次地址翻译硬件将一个虚拟地址转换成物理地址时都会读取页表

上图展示了一个页表的基本结构,页表就是一个页表条目(Page Table Entry,PTE)的数组。虚拟地址空间中的每个页在页表中都有一个 PTE。在这里我们假设每个 PTE 是由一个有效位(Valid bit)和一个 n 位地址字段组成的。有效位表明了该虚拟页当前是否被缓存在 DRAM 中。如果有效位为 1,那么地址字段就表示 DRAM 中相应的物理页的起始位置,这个物理页缓存了该虚拟页。如果有效位为 0,那么一个 null 地址表示这个虚拟页还未被分配,否则对应的这个地址就指向该虚拟页在磁盘上的起始位置。
上图所示中一共有 8 个虚拟页和 4 个物理页的页表,4 个虚拟页 VP1, VP2, VP4, VP7 当前被缓存在 DRAM 中,VP0 和 VP5 还未被分配,而剩下的 VP3 和 VP6 已经被分配了,但是当前未被缓存。
在程序整个运作过程中,程序引用的不同页面的总数可能超出了物理内存的总大小,但是局部性原则可以保证在任意时刻,程序将趋向于在一个较小的活动页面(active page)集合上工作,这个集合被称作工作集(working set)或者常驻集合(resident set)。在程序初始开销之后也就是将工作集页面调入主存,接下来对这个工作集的访问会产生命中,这样就不会产生额外的磁盘消耗。 如果程序有良好的时间局部性,那么虚拟内存将工作的非常好。如果程序没有良好的时间局部性也就是工作集的大小超出了主存的大小,那么程序将会进入一个称作 抖动(thrashing)的状态,这个时候页面将不断地换进换出,程序会出现性能问题。
虚拟内存大大简化了内存管理,操作系统为每个进程提供了一个独立的虚拟地址空间。

在上图中,进程 1 的页表将 VP1 映射到 PP2, VP2 映射到 PP6。进程 2 的页表将 VP1 映射到 PP8, VP2 映射到 PP6。在这里可以看到多个虚拟页面可以映射到同一个共享的物理页面上。
按需页面调度和独立的虚拟地址空间的结合,让 虚拟内存简化了链接和加载,代码和数据共享,以及应用程序的内存分配。
- 简化链接。独立的地址空间允许每个进程的内存映像使用相同的基本格式,而不管代码和数据实际存放在物理内存的何处。
- 简化加载。虚拟内存使得容易向内存中加载可执行文件和共享对象文件。将一组连续的虚拟页面映射到任意一个文件中的任意位置的表示法称作内存映射(memory mapping)。Linux 提供了一个 nmap 的系统调用,允许应用程序自己做内存映射。
- 简化共享。独立地址空间为操作系统提供了一个管理用户进程和操作系统自身之间共享的一致机制。一般情况下,每个进程都有自己私有的代码、数据、堆栈。这些内容不与其他进程共享。在这种情况下,操作系统创建页表,将相应的虚拟页映射到不连续的物理页面。
- 简化内存分配。虚拟内存向用户进程提供一个简单的分配额外内存的机制。当一个用户程序要求额外的堆空间时候,操作系统分配 k 个适当的连续的虚拟内存页面,并且将他们映射到物理内存的中的 k 个任意页面,操作系统没有必要分配 k 个连续的物理内存页面。
内核线程是操作系统内核支持的线程,在内核中有一个线程表用来记录系统中的所有线程,创建或者销毁一个线程时,都需要涉及到系统调用,然后再内核中对线程表进行更新操作。对内核线程的阻塞以及其它操作,都涉及到系统调用,系统调用的代价都比较大,涉及到在用户态和内核态之间的来回切换。此外,内核内部有线程调度器,用于决定应该将 CPU 时间片分配个哪个线程。 程序一般不会直接操作内核线程,而是使用内核线程的一种高级接口,轻量级进程。轻量级进程与内核线程之间的关系是 1:1,每一个轻量级进程内部都有一个内核线程支持。图中, LWP 指 Light Weight Process,即轻量级进程;KLT 指 Kernel Level Thread,即内核线程。

用户线程是程序或者编程语言自己实现的线程库,系统内核无法感知到这些线程的存在。用户线程的建立、同步、销毁和调度,都在用户态中完成,无须内核的帮助,不需要进行系统调用,这样的好处是对于线程的操作是非常高效的。在这种情况下,进程和用户线程的比例是 1 :N。

用户态线程面对如何阻塞线程时,会面临困难,阻塞一个用户态线程会出现把整个进程都阻塞的情况,多线程也就失去了意义。因为缺少内核的支持,所以很多需要利用内核才能完成的工作,例如阻塞与唤醒线程、多 CPU 环境下线程的映射等,都需要用户程序去实现,实现起来会异常困难。
**前两者混合实现:**在这种混合实现下,既存在用户线程,也存在内核线程。用户态线程的创建、切换这些操作依然很高效,并且用户态实现的线程,比较容易加大线程的规模。需要操作系统内核支持的功能,则通过内核线程来做到,例如映射到不同的处理器上、处理线程的阻塞与唤醒以及内核线程的调度等。这种实现依然会使用到轻量级进程 LWP,它是用户线程和内核线程之间的桥梁。

在 JDK1.2 之前, Java 的线程是使用用户线程实现的,在 JDK1.2 之后,Java 才采用操作系统原生支持的线程模型来实现,Java 线程模型的实现方式,主要取决于操作系统。对于 Oracle JDK 来说,在 Windows 和 Linux 上的线程模型是采用一对一的方式实现的,即一条 Java 线程映射到一条轻量级进程(内核线程)。而在 Solaris 平台中,Java 则支持 1 :1 和 N : M 的线程模型。
地址映射过程中,若在页面中发现所要访问的页面不在内存中,则发生缺页中断 。
缺页中断 就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问。 在这个时候,被内存映射的文件实际上成了一个分页交换文件。
当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则。
- OPT 页面置换算法(最佳页面置换算法) :最佳(Optimal, OPT)置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现。一般作为衡量其他置换算法的方法。
- FIFO(First In First Out) 页面置换算法(先进先出页面置换算法) : 总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。
- LRU (Least Currently Used)页面置换算法(最近最久未使用页面置换算法) :LRU算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。
- LFU (Least Frequently Used)页面置换算法(最少使用页面置换算法) : 该置换算法选择在之前时期使用最少的页面作为淘汰页。
局部性原理表现在以下两个方面:
- 时间局部性 :如果程序中的某条指令一旦执行,不久以后该指令可能再次执行;如果某数据被访问过,不久以后该数据可能再次被访问。产生时间局部性的典型原因,是由于在程序中存在着大量的循环操作。
- 空间局部性 :一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。
时间局部性是通过将近来使用的指令和数据保存到高速缓存存储器中,并使用高速缓存的层次结构实现。空间局部性通常是使用较大的高速缓存,并将预取机制集成到高速缓存控制逻辑中实现。虚拟内存技术实际上就是建立了 “内存一外存”的两级存储器的结构,利用局部性原理实现髙速缓存。
基于局部性原理,在程序装入时,可以将程序的一部分装入内存,而将其他部分留在外存,就可以启动程序执行。由于外存往往比内存大很多,所以我们运行的软件的内存大小实际上是可以比计算机系统实际的内存大小大的。在程序执行过程中,当所访问的信息不在内存时,由操作系统将所需要的部分调入内存,然后继续执行程序。另一方面,操作系统将内存中暂时不使用的内容换到外存上,从而腾出空间存放将要调入内存的信息。这样,计算机好像为用户提供了一个比实际内存大的多的存储器——虚拟存储器。
VFS即虚拟文件系统是Linux文件系统中的一个抽象软件层;因为它的支持,众多不同的实际文件系统才能在Linux中共存,跨文件系统操作才能实现。VFS借助它四个主要的数据结构即超级块、索引节点、目录项和文件对象以及一些辅助的数据结构,向Linux中不管是普通的文件还是目录、设备、套接字等都提供同样的操作界面,如打开、读写、关闭等。只有当把控制权传给实际的文件系统时,实际的文件系统才会做出区分,对不同的文件类型执行不同的操作。由此可见,正是有了VFS的存在,跨文件系统操作才能执行,Unix/Linux中的“一切皆是文件”的口号才能够得以实现。
“一切皆是文件”是 Unix/Linux 的基本哲学之一。不仅普通的文件,目录、字符设备、块设备、 套接字等在 Unix/Linux 中都是以文件被对待;它们虽然类型不同,但是对其提供的却是同一套操作界面。
Linux 中允许众多不同的文件系统共存,如 ext2, ext3, vfat 等。通过使用同一套文件 I/O 系统 调用即可对 Linux 中的任意文件进行操作而无需考虑其所在的具体文件系统格式;更进一步,对文件的 操作可以跨文件系统而执行。如图 1 所示,我们可以使用 cp 命令从 vfat 文件系统格式的硬盘拷贝数据到 ext3 文件系统格式的硬盘;而这样的操作涉及到两个不同的文件系统。

虚拟文件系统(Virtual File System, 简称 VFS), 是 Linux 内核中的一个软件层,用于给用户空间的程序提供文件系统接口;同时,它也提供了内核中的一个 抽象功能,允许不同的文件系统共存。系统中所有的文件系统不但依赖 VFS 共存,而且也依靠 VFS 协同工作。为了能够支持各种实际文件系统,VFS 定义了所有文件系统都支持的基本的、概念上的接口和数据 结构;同时实际文件系统也提供 VFS 所期望的抽象接口和数据结构,将自身的诸如文件、目录等概念在形式 上与VFS的定义保持一致。换句话说,一个实际的文件系统想要被 Linux 支持,就必须提供一个符合VFS标准 的接口,才能与 VFS 协同工作。实际文件系统在统一的接口和数据结构下隐藏了具体的实现细节,所以在VFS 层和内核的其他部分看来,所有文件系统都是相同的。上图显示了VFS在内核中与实际的文件系统的协同关系。
我们已经知道,正是由于在内核中引入了VFS,跨文件系统的文件操作才能实现,“一切皆是文件” 的口号才能承诺。而为什么引入了VFS,就能实现这两个特性呢?在接下来,我们将以这样的一个思路来切入 文章的正题:我们将先简要介绍下用以描述VFS模型的一些数据结构,总结出这些数据结构相互间的关系;然后 选择两个具有代表性的文件I/O操作sys_open()和sys_read()来详细说明内核是如何借助VFS和具体的文件系统打 交道以实现跨文件系统的文件操作和承诺“一切皆是文件”的口号。
从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。为了描述 这个结构,Linux引入了一些基本概念:
文件 一组在逻辑上具有完整意义的信息项的系列。在Linux中,除了普通文件,其他诸如目录、设备、套接字等 也以文件被对待。总之,“一切皆文件”。Linux系统上的/proc目录是一种文件系统,即proc文件系统。与其它常见的文件系统不同的是,/proc是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。
目录 目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成 文件路径。在Linux中,目录也是以一种特殊文件被对待的,所以用于文件的操作同样也可以用在目录上。
目录项 在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项。
索引节点 用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同 的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。
超级块 用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节 点数等,存放于磁盘的特定扇区中。
如上的几个概念在磁盘中的位置关系如下图所示。

创建 以某种方式格式化磁盘的过程就是在其之上建立一个文件系统的过程。创建文现系统时,会在磁盘的特定位置写入 关于该文件系统的控制信息。
注册 向内核报到,声明自己能被内核支持。一般在编译内核的时侯注册;也可以加载模块的方式手动注册。注册过程实 际上是将表示各实际文件系统的数据结构struct file_system_type 实例化。
安装 也就是我们熟悉的mount操作,将文件系统加入到Linux的根文件系统的目录树结构上;这样文件系统才能被访问。
VFS依靠四个主要的数据结构和一些辅助的数据结构来描述其结构信息,这些数据结构表现得就像是对象; 每个主要对象中都包含由操作函数表构成的操作对象,这些操作对象描述了内核针对这几个主要的对象可以进行的操作。
超级块对象
存储一个已安装的文件系统的控制信息,代表一个已安装的文件系统;每次一个实际的文件系统被安装时, 内核会从磁盘的特定位置读取一些控制信息来填充内存中的超级块对象。一个安装实例和一个超级块对象一一对应。 超级块通过其结构中的一个域s_type记录它所属的文件系统类型。
索引节点对象
索引节点对象存储了文件的相关信息,代表了存储设备上的一个实际的物理文件。当一个 文件首次被访问时,内核会在内存中组装相应的索引节点对象,以便向内核提供对一个文件进行操 作时所必需的全部信息;这些信息一部分存储在磁盘特定位置,另外一部分是在加载时动态填充的。
目录项对象
引入目录项的概念主要是出于方便查找文件的目的。一个路径的各个组成部分,不管是目录还是 普通的文件,都是一个目录项对象。如,在路径/home/source/test.c中,目录 /, home, source和文件 test.c都对应一个目录项对象。不同于前面的两个对象,目录项对象没有对应的磁盘数据结构,VFS在遍 历路径名的过程中现场将它们逐个地解析成目录项对象。
文件对象是已打开的文件在内存中的表示,主要用于建立进程和磁盘上的文件的对应关系。它由sys_open() 现场创建,由sys_close()销毁。文件对象和物理文件的关系有点像进程和程序的关系一样。当我们站在用户空间来看 待VFS,我们像是只需与文件对象打交道,而无须关心超级块,索引节点或目录项。因为多个进程可以同时打开和操作 同一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已经打开的文件,它 反过来指向目录项对象(反过来指向索引节点)。一个文件对应的文件对象可能不是惟一的,但是其对应的索引节点和 目录项对象无疑是惟一的。
将vfat格式的磁盘上的一个文件a.txt拷贝到ext3格式的磁盘上,命名为b.txt。这包含两个过程,对a.txt进行读操作,对b.txt进行写操作。读写操作前,需要先打开文件。由前面的分析可知,打开文件时,VFS会知道该文件对应的文件系统格式,以后操作该文件时,VFS会调用其对应的实际文件系统的操作方法。所以,VFS调用vfat的读文件方法将a.txt的数据读入内存;在将a.txt在内存中的数据映射到b.txt对应的内存空间后,VFS调用ext3的写文件方法将b.txt写入磁盘;从而实现了最终的跨文件系统的复制操作。
不论是普通的文件,还是特殊的目录、设备等,VFS都将它们同等看待成文件,通过同一套文件操作界面来对它们进行操作。操作文件时需先打开;打开文件时,VFS会知道该文件对应的文件系统格式;当VFS把控制权传给实际的文件系统时,实际的文件系统再做出具体区分,对不同的文件类型执行不同的操作。这也就是“一切皆是文件”的根本所在。
缓存就是用来避免频繁的到数据库或磁盘文件获取数据而建立的一个快速临时存储器。一般来说,缓存比数据库或磁盘容量更小,但是存取速度非常快。一般来说,内存是当前技术下最廉价且有效的缓存介质。内存价格低廉,但是存取速度是一般磁盘IO无法比拟的。用于存储频繁访问的数据,临时存储耗时的计算结果,内存缓存减少磁盘IO。
应用层缓存这块跟开发人员关系最大,也是平时经常接触的。
- 1、缓存数据库的查询结果,减少数据的压力。这个在大型网站是必须做的。
- 2、缓存磁盘文件的数据。比如常用的数据可以放到内存,不用每次都去读取磁盘,特别是密集计算的程序,比如中文分词的词库。
- 3、缓存某个耗时的计算操作,比如数据统计。
应用层缓存的架构也可以分几种:
- 1、嵌入式,也就是缓存和应用在同一个机器。比如单机的文件缓存,java中用hashMap来缓存数据等等。这种缓存速度快,没有网络消耗。
- 2、分布式缓存,把缓存的数据独立到不同的机器,通过网络来请求数据,比如常用的memcache就是这一类。
分布式缓存一般可以分为几种:
- 1、按应用切分数据到不同的缓存服务器,这是一种比较简单和实用的方式。
- 2、按照某种规则(hash,路由等等)把数据存储到不同的缓存服务器。
- 3、代理模式,应用在获取数据的时候都由代理透明的处理,缓存机制有代理服务器来处理。
DRAM只能将数据保持很短的时间。为了保持数据,DRAM使用电容存储,所以必须隔一段时间刷新(预充电)一次,如果存储单元没有被刷新,存储的信息就会丢失(关机就会丢失数据)。 主要用于系统内存 。
SRAM是一种具有静止存取功能的内存,不需要刷新电路即能保存它内部存储的数据,速度快,但是集成度低。 主要用于CPU与主存之间的高速缓存 。
Cache不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。在计算机存储系统的层次结构中,介于中央处理器和主存储器之间的高速小容量存储器。它和主存储器一起构成一级的存储器。高速缓冲存储器和主存储器之间信息的调度和传送是由硬件自动进行的。 高速缓冲存储器最重要的技术指标是它的命中率 。Cache作为主存局部区域的副本,用来存放当前活跃的程序和数据,它利用程序运行的局部性,把局部范围的数据从主存复制到Cache中,使CPU直接高速从Cache中读取程序和数据,从而解决CPU速度和主存速度不匹配的问题。
主要由三大部分组成:
-
Cache存储体:存放由主存调入的指令与数据块。
-
地址转换部件:建立目录表以实现主存地址到缓存地址的转换。
-
替换部件:在缓存已满时按一定策略进行数据块替换,并修改地址转换部件。
CPU在Cache中找到有用的数据被称为命中,当Cache中没有CPU所需的数据时(这时称为未命中),CPU才访问内存。为了保证CPU访问时有较高的命中率,Cache中的内容应该按一定的算法替换。
当出现未命中而高速存储器对应列中没有空的位置时,便淘汰该列中的某一组以腾出位置存放新调入的组,这称为替换。确定替换的规则叫替换算法,常用的替换算法有:最近最少使用法(LRU)、先进先出法(FIFO)和随机法(RAND)等。
高速缓冲存储器 Cache 的出现使 CPU 可以不直接访问主存,而与高速 Cache 交换信息,解决了主存与 CPU 速度不匹配的问题。 Cache 的替换算法的目标是使Cache 获得更高的命中率,掌握不同的 Cache 替换算法及各自的特点可以帮助我们认识 Cache 访存的局部性原理。
在多体并行存储系统中,由于 I/O 设备向主存请求的级别高于 CPU 访存,这就出现了 CPU 等待 I/O 设备访存的现象,致使 CPU 空等一段时间,甚至可能等待几个主存周期,从而降低了 CPU 的工作效率。为了避免 CPU 与 I/O 设备争抢访存,可在CPU 与主存之间加一级缓存,这样,主存可将 CPU 要取的信息提前送至缓存,一旦主存在与 I/O 设备交换时, CPU 可直接从缓存中读取所需信息,不必空等而影响效率。
目前提出的算法可以分为以下三类(第一类是重点要掌握的):
- 传统替换算法及其直接演化,其代表算法有 :
- **LRU( Least Recently Used)**算法:将最近最少使用的内容替换出Cache ;
- **LFU( Lease Frequently Used)**算法:将访问次数最少的内容替换出Cache;
- 如果Cache中所有内容都是同一天被缓存的,则将最大的文档替换出Cache,否则按LRU算法进行替换 。
- FIFO(First In First Out):遵循先入先出原则,若当前Cache被填满,则替换最早进入Cache的那个。
- 基于缓存内容关键特征的替换算法,其代表算法有:
- Size替换算法:将最大的内容替换出Cache
- LRU— MIN替换算法:该算法力图使被替换的文档个数最少。设待缓存文档的大小为S,对Cache中缓存的大小至少是S的文档,根据LRU算法进行替换;如果没有大小至少为S的对象,则从大小至少为S/2的文档中按照LRU算法进行替换;
- LRU—Threshold替换算法:和LRU算法一致,只是大小超过一定阈值的文档不能被缓存;
- Lowest Lacency First替换算法:将访问延迟最小的文档替换出Cache。
- 基于代价的替换算法,该类算法使用一个代价函数对Cache中的对象进行评估,最后根据代价值的大小决定替换对象。其代表算法有:
- Hybrid算法:算法对Cache中的每一个对象赋予一个效用函数,将效用最小的对象替换出Cache;
- Lowest Relative Value算法:将效用值最低的对象替换出Cache;
- Least Normalized Cost Replacement(LCNR)算法:该算法使用一个关于文档访问频次、传输时间和大小的推理函数来确定替换文档;
- Bolot等人 提出了一种基于文档传输时间代价、大小、和上次访问时间的权重推理函数来确定文档替换;
- Size—Adjust LRU(SLRU)算法:对缓存的对象按代价与大小的比率进行排序,并选取比率最小的对象进行替换。
- 写直达法 CPU在执行写操作时,必须把数据同时写入Cache和主存。当某一块需要替换时,也不必把这一块写回到主存中,新调入的块可以可以立即把在Cache的这一块覆盖。 这种方法实现简单,而且能随时保持主存数据的正确性,但可能增加多次不必要的主存写入,降低存取速度。
- 写回法 CPU在执行写操作时,被写数据只写入Cache,不写入主存。仅当需要替换时,才把已经修改过的Cache块写回到主存。 采用这种方法时需要一个标志位,来标记一个块中的任一单元是否被修改。若被修改,则标志位置1。在需要替换掉这一块时,如果标志位为1,则必须先把这一块写回到主存中,然后才能调入新的块;否则则不必写回主存。 这种方法操作速度快,但因主存中的字块未及时修改而有可能出错。
ps 查看进程
top:监控linux的系统状况,比如cpu、内存的使用。
netstat 查看路由表
ifconfig 查看ip
r 代表运行和等待cpu时间片的进程数,原则上整个系统不要超过核数*2,否则代表压力过大。
b表示等待系统资源,如磁盘或者网络IO
us用户进程消耗cpu占比, sy系统进程消耗cpu占比
pidstate查看进程占用cpu -p pid -r 采样
free查看内存
df -h 人性化显示disk剩余空间
iostat查看io操作相关
ifstate查看网络io状态
1 top命令找出cpu占比最高的
2 ps-ef/jps -l 定位后台进程编号
3 定位到线程
4 十进制的线程id转换为16进制如5102-13ee
5 查看具体代码行
终端登录:
当系统自举时,内核创建ID为1的进程,也就是init进程,init进程系统进入多用户状态。
init进程读取/etc/inittab,对每一个允许登录的终端设备,init调用一次fork,它所生成的子进程执行(exec)getty程序。
getty为终端设备调用open函数,如果没有请求则阻塞,如果有请求,则文件描述符0,1,2就设置到该设备,然后getty输出”login“等的信息并等带用户输入用户名。
当用户键入用户名后,getty的工作就完成了。
然后以类似于这样的方式调用login程序
execle(“/bin/login”,“login”,“-p”,username,(char*)0,envp);
init以空环境(即无envp参数)调用一个getty,gettty以终端名和gettytab中说明的环境字符串。-p标识通知login保留传递给它的环境,也可将其他环境字符串加到该环境中,但
是不要替换它。
一、进程
传统上,Unix操作系统下运行的应用程序、 服务器以及其他程序都被称为进程,而Linux也继承了来自unix进程的概念。必须要理解下,程序是指的存储在存储设备上(如磁盘)包含了可执行机器指 令(二进制代码)和数据的静态实体;而进程可以认为是已经被OS从磁盘加载到内存上的、动态的、可运行的指令与数据的集合,是在运行的动态实体。这里指的 指令和数据的集合可以理解为Linux上ELF文件格式中的.text .data数据段
二、进程组
每个进程除了有一个进程ID之外,还属于一个进程组,那什么是进程组呢? 顾名思义,进程组就是一个或多个进程的集合。这些进程并不是孤立的,他们彼此之间或者存在父子、兄弟关系,或者在功能上有相近的联系。每个进程都有父进程,而所有的进程以init进程为根,形成一个树状结构。
那为啥Linux里要有进程组呢?其实,提供进程组就是为了方便对进程进行管理。假设要完成一个任务,需要同时并发100个进程。当用户处于某种原因要终止 这个任务时,要是没有进程组,就需要手动的一个个去杀死这100个进程,并且必须要严格按照进程间父子兄弟关系顺序,否则会扰乱进程树。有了进程组,就可以将这100个进程设置为一个进程组,它们共有1个组号(pgrp),并且有选取一个进程作为组长(通常是“辈分”最高的那个,通常该进程的ID也就作为进程组的ID)。现在就可以通过杀死整个进程组,来关闭这100个进程,并且是严格有序的。组长进程可以创建一个进程组,创建该组中的进程,然后终止。只要在某个进程组中一个进程存在,则该进程组就存在,这与其组长进程是否终止无关。进程必定属于一个进程组,也只能属于一个进程组。 一个进程组中可以包含多个进程。 进程组的生命周期从被创建开始,到其内所有进程终止或离开该组。内核中,sys_getpgrp()系统调用用来获取当前进程所在进程组号;sys_setpgid(int pid, int pgid)调用用来设置置顶进程pid的进程组号为pgid。
三、作业 一个正在执行的进程称为一个作业,而且作业可以包含一个或多个进程,尤其是当使用了管道和重定向命令。例如“nroff -man ps.1|grep kill|more”这个作业就同时启动了三个进程。 作业控制指的是控制正在运行的进程的行为。比如,用户可以挂起一个进程,等一会儿再继续执行该进程。shell将记录所有启动的进程情况,在每个进程过程中,用户可以任意地挂起进程或重新启动进程。作业控制是许多shell(包括bash和tcsh)的一个特性,使用户能在多个独立作业间进行切换。 一 般而言,进程与作业控制相关联时,才被称为作业。
在大多数情况下,用户在同一时间只运行一个作业,即它们最后向shell键入的命令。但是使用作业控制,用户可以同时运行多个作业,并在需要时在这些作业间进行切换。这会有什么用途呢?例如,当用户编辑一个文本文件,并需要中止编辑做其他事情时,利用作业控制,用户可以让编辑器暂时挂起,返回shell提示符开始做其他的事情。其他事情做完以后,用户可以重新启动挂起的编辑器,返回到刚才中止的地方,就象用户从来没有离开编辑器一样。这只是一个例子,作业控制还有许多其他实际的用途。
作业控制(jobcontrol)是shell的另一个特性,它允许用户同时运行多个作业而产生,并且根据需求可将前后台的作业进行切换。当启动某个作业时,它通常是运行在前台,因此该作业是与终端相连接的。利用作业控制这一功能,可将正处于前台工作的作业切换到后台去,在后台该作业可继续运行,并且在前台可以监视另一个作业。如果想关注一下某个正在后台运行的作业,那么可将其切换到前台工作,以使其又一次与终端相连接。作业控制的这一概念起源于BSDUNIX,后来又出现在CShell中。
四、会话
再看下会话。由于Linux是多用户多任务的分时系统,所以必须要支持多个用户同时使用一个操作系统。当一个用户登录一次系统就形成一次会话 。一个会话可包含多个进程组,但只能有一个前台进程组。每个会话都有一个会话首领(leader),即创建会话的进程。 sys_setsid()调用能创建一个会话。必须注意的是,只有当前进程不是进程组的组长时,才能创建一个新的会话。调用setsid 之后,该进程成为新会话的leader。
一个会话可以有一个控制终端。这通常是登陆到其上的终端设备(在终端登陆情况下)或伪终端设备(在网络登陆情况下)。建立与控制终端连接的会话首进程被称为控制进程。一个会话中的几个进程组可被分为一个前台进程组以及一个或多个后台进程组。所以一个会话中,应该包括控制进程(会话首进程),一个前台进程组和任意后台进程组。 一次登录形成一个会话,一个会话可包含多个进程组,但只能有一个前台进程组。
五、控制终端
会话的领头进程打开一个终端之后, 该终端就成为该会话的控制终端 (SVR4/Linux)
与控制终端建立连接的会话领头进程称为控制进程 (session leader)
一个会话只能有一个控制终端
产生在控制终端上的输入和信号将发送给会话的前台进程组中的所有进程
终端上的连接断开时 (比如网络断开或 Modem 断开), 挂起信号将发送到控制进程(session leader)
进程属于一个进程组,进程组属于一个会话,会话可能有也可能没有控制终端。一般而言,当用户在某个终端上登录时,一个新的会话就开始了。进程组由组中的领头进程标识,领头进程的进程标识符就是进程组的组标识符。类似地,每个会话也对应有一个领头进程。 同一会话中的进程通过该会话的领头进程和一个终端相连,该终端作为这个会话的控制终端。一个会话只能有一个控制终端,而一个控制终端只能控制一个会话。用户通过控制终端,可以向该控制终端所控制的会话中的进程发送键盘信号。
shell可以同时运行一个前台作业和任意多个后台作业,一个前台作业可以由多个进程组成,一个后台作业也可以由多个进程组成,这称为作业控制。可以通过fg和bg命令控制作业的前后台运行。由于一个session只能有一个前台进程组,如果某个进程组需要在前台运行,shell所在的进程组就自动变为后台进程组。
孤儿进程组
POSIX定义为:孤儿进程指的是在其父进程执行完成或被终止后仍继续运行的一类进程。这些孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。(一个进程组中的所有进程的父进程要么是该进程组的一个进程,要么不是该进程组所在的会话中的进程。一个进程组不是孤儿进程组的条件是,该组中有一个进程其父进程在属于同一个会话的另一个组中。)
简单来说:有bash产生的新进程组中,至少有一个进程的PPID指向该bash,否则该进程组成为孤儿进程组,无法将进程状态改变通知bash
POSIX要求系统向孤儿进程中处于停止状态的每一个进程发送挂断信号(SIGHUP),接着又向其发送继续信号(SIGCONT)对挂断信号的默认动作是终止该进程(注意终止
进程和停止进程是有区别的,停止指暂停,终止指退出)
为什么有孤儿进程组
当一个终端控制进程(即会话首进程)终止后,那么这个终端可以用来建立一个新的会话。这可能会产生一个问题,原来旧的会话(一个或者多个进程组的集合)中的任一进程可再次访问这个的终端。为了防止这类问题的产生,于是就有了孤儿进程组的概念。当一个进程组成为孤儿进程组时,posix.1要求向孤儿进程组中处于停止状态的进程发送SIGHUP(挂起)信号,系统对于这种信号的默认处理是终止进程,然而如果无视这个信号或者另行处理的话那么这个挂起进程仍可以继续执行。
有孤儿进程,对应的也有孤儿进程组的概念。为何引入这个概念以及这个概念的引入需要OS的实现者作些什么呢?先看两个前提,首先,posix用一个session的概念来描述一次用户的登录以及该用户在此次登录后的操作,然后用作业的概念描述不同操作的内容,最后才用进程的概念描述不同操作中某一个具体的工作;其次,unix最初将所有的进程组织成了树的形式,这样就便于追踪每个进程也便于管理,有了上述两个前提事情就很明白了,一切都是为了便于管理,一切都是为了登录用户的安全,即此次登录用户的作业是不能被下个登录用户所控制的,即使它们的用户名一致也是不行的,因此所谓的孤儿进程组简单点说就是脱离了创造它的session控制的,离开其session眼线的进程组,unix中怎样控制进程,怎样证明是否在自己的眼线内,那就是树形结构了,只要处于以自己为根的子树的进程就是自己眼线内的进程,这个进程就是受到保护的,有权操作的,而在别的树枝上的进程原则上是触动不得的,unix中建立进程使用fork,自然地这么一“叉子”就形成了自己的一个树枝,当然在自己眼线了,一般对于登录用户而言一个会话起始于一次login之后的shell,只要该用户不logout,在该终端的shell上执行的所有的非守护进程都是该shell的后代进程,因此它们组成一个会话,全部在shell的眼线中,一个会话终止于会话首长的death。现在考虑一下终端上的shell退出后的情景,按照规定,该终端上所有的进程都过继给了别的进程,大多数情况是init进程,然后紧接着另外一个用户登录了这个终端或者知道前一个登录用户密钥的另一个有不好念头的人登录了该终端,当然为其启动的shell创建了一个新的session,由于之前登录的用户已退出,现在登录的用户由于之前用户的进程组都成了孤儿进程组,所以它再有恶意也不能控制它们了,那些孤儿进程组中的成员要么继续安全的运行,要么被shell退出时发出的SIGHUP信号杀死。一般一个登录shell就是一个会话首进程,会话首进程获得一个控制终端给前台进程组用,会话首进程也只能通过控制终端来控制别的进程,所谓的控制就是发送信号(如ctl+c等)
僵尸进程
我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
子进程结束,父进程没有明确的答复操作系统内核:已收到子进程结束的消息。此时操作系统内核会一直保存该子进程的部分PCB信息,同时将进程的状态置为defunct--->僵尸进程
通过ps -ef | grep "xxx"找到僵尸进程的PID,通过kill -9 PID,也不能强制杀死;即僵尸进程是不能够被直接消除掉的
**僵尸进程的危害:**占用PCB资源(主要是PID资源),系统将会因为产生大量的僵尸进程,而没有可用的进程号来产生新进程,导致系统资源不足。
僵尸进程的三种解决方案:
**核心思想:**父进程的知道子进程的结束,并且明确的回复操作系统,此时操作系统才能回收PCB资源,避免僵尸进程的产生
此时父进程需要处理子进程的结束,需要调用wait()、waitpid()函数族;wait()会等待子进程的结束,调用wait()的进程会阻塞,直到接收到子进程的消息才被唤醒;子进程结束时,会给父进程发送SIGCHLD(17)信号
(1)、wait()用的场合:只能在父子进程中,父进程等待子进程的结束,一直在阻塞,信号通知父进程,避免了子进程的僵尸状态
wait()方法只能在具有子进程的进程中使用,如果一个进程没有子进程,调用wait()方法会失败
wait()方法是用于处理子进程结束状态的,同时让父进程明确告知操作系统内核已经处理了子进程的结束,从而使得操作系统能够彻底回收子进程的PCB信息
(2)、:将僵尸进程的父进程exit()结束掉,此时僵尸进程被init进程接收; 例如有个进程,它定期的产生一个子进程,这个子进程需要做的事情很少,做完它该做的事情之后就退出了,因此这个子进程的生命周期很短,但是,父进程只管生成新的子进程,至于子进程 退出之后的事情,则一概不闻不问,这样,系统运行上一段时间之后,系统中就会存在很多的僵死进程,倘若用ps命令查看的话,就会看到很多状态为Z的进程。 严格地来说,僵死进程并不是问题的根源,罪魁祸首是产生出大量僵死进程的那个父进程。因此,当我们寻求如何消灭系统中大量的僵死进程时,答案就是把产生大 量僵死进程的那个元凶枪毙掉(也就是通过kill发送SIGTERM或者SIGKILL信号啦)。枪毙了元凶进程之后,它产生的僵死进程就变成了孤儿进 程,这些孤儿进程会被init进程接管,init进程会wait()这些孤儿进程,释放它们占用的系统进程表中的资源,这样,这些已经僵死的孤儿进程 就能瞑目而去了。
(3)、:写一个信号处理函数,signal(SIGCHLD, 函数指针),在信号处理函数中调用wait()即可,此时父进程就会知道子进程结束,会明确的回复操作系统(就是当子进程结束时,信号处理函数接收到SIGCHLD信号时,方才调用wait(),此时父进程才阻塞)
以上的解决方案:
方案一:使父进程长时间的阻塞
方案二:使父进程必须的结束掉
方案三:即可解决父进程的阻塞,又可避免僵尸进程的产生
守护进程
Linux Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。它不需要用户输入就能运行而且提供某种服务,不是对整个系统就是对某个用户程序提供服务。Linux系统的大多数服务器就是通过守护进程实现的。常见的守护进程包括系统日志进程syslogd、 web服务器httpd、邮件服务器sendmail和数据库服务器mysqld等。
守护进程一般在系统启动时开始运行,除非强行终止,否则直到系统关机都保持运行。守护进程经常以超级用户(root)权限运行,因为它们要使用特殊的端口(1-1024)或访问某些特殊的资源。
一个守护进程的父进程是init进程,因为它真正的父进程在fork出子进程后就先于子进程exit退出了,所以它是一个由init继承的孤儿进程。守护进程是非交互式程序,没有控制终端,所以任何输出,无论是向标准输出设备stdout还是标准出错设备stderr的输出都需要特殊处理。
守护进程的名称通常以d结尾,比如sshd、xinetd、crond等
编写守护进程的一般步骤步骤:
(1)在父进程中执行fork并exit推出;
(2)在子进程中调用setsid函数创建新的会话;
(3)在子进程中调用chdir函数,让根目录 ”/” 成为子进程的工作目录;
(4)在子进程中调用umask函数,设置进程的umask为0;
(5)在子进程中关闭任何不需要的文件描述符
说明:
-
在后台运行。 为避免挂起控制终端将Daemon放入后台执行。方法是在进程中调用fork使父进程终止,让Daemon在子进程中后台执行。 if(pid=fork()) exit(0);//是父进程,结束父进程,子进程继续
-
脱离控制终端,登录会话和进程组 有必要先介绍一下Linux中的进程与控制终端,登录会话和进程组之间的关系:进程属于一个进程组,进程组号(GID)就是进程组长的进程号(PID)。登录会话可以包含多个进程组。这些进程组共享一个控制终端。这个控制终端通常是创建进程的登录终端。 控制终端,登录会话和进程组通常是从父进程继承下来的。我们的目的就是要摆脱它们,使之不受它们的影响。方法是在第1点的基础上,调用setsid()使进程成为会话组长: setsid(); 说明:当进程是会话组长时setsid()调用失败。但第一点已经保证进程不是会话组长。setsid()调用成功后,进程成为新的会话组长和新的进程组长,并与原来的登录会话和进程组脱离。由于会话过程对控制终端的独占性,进程同时与控制终端脱离。
-
禁止进程重新打开控制终端 现在,进程已经成为无终端的会话组长。但它可以重新申请打开一个控制终端。可以通过使进程不再成为会话组长来禁止进程重新打开控制终端: if(pid=fork()) exit(0);//结束第一子进程,第二子进程继续(第二子进程不再是会话组长)
-
关闭打开的文件描述符 进程从创建它的父进程那里继承了打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。按如下方法关闭它们: for(i=0;i 关闭打开的文件描述符close(i);>
-
改变当前工作目录 进程活动时,其工作目录所在的文件系统不能卸下。一般需要将工作目录改变到根目录。对于需要转储核心,写运行日志的进程将工作目录改变到特定目录如/tmpchdir("/")
-
重设文件创建掩模 进程从创建它的父进程那里继承了文件创建掩模。它可能修改守护进程所创建的文件的存取位。为防止这一点,将文件创建掩模清除:umask(0);
-
处理SIGCHLD信号 处理SIGCHLD信号并不是必须的。但对于某些进程,特别是服务器进程往往在请求到来时生成子进程处理请求。如果父进程不等待子进程结束,子进程将成为僵尸进程(zombie)从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux下可以简单地将SIGCHLD信号的操作设为SIG_IGN。 signal(SIGCHLD,SIG_IGN); 这样,内核在子进程结束时不会产生僵尸进程。这一点与BSD4不同,BSD4下必须显式等待子进程结束才能释放僵尸进程。