Thread Pool
This document describes the overall architecture of the thread pool and the scheduling of tasks onto those. The document does neither describe the complete nor exact API. The task model is described in Task Model.
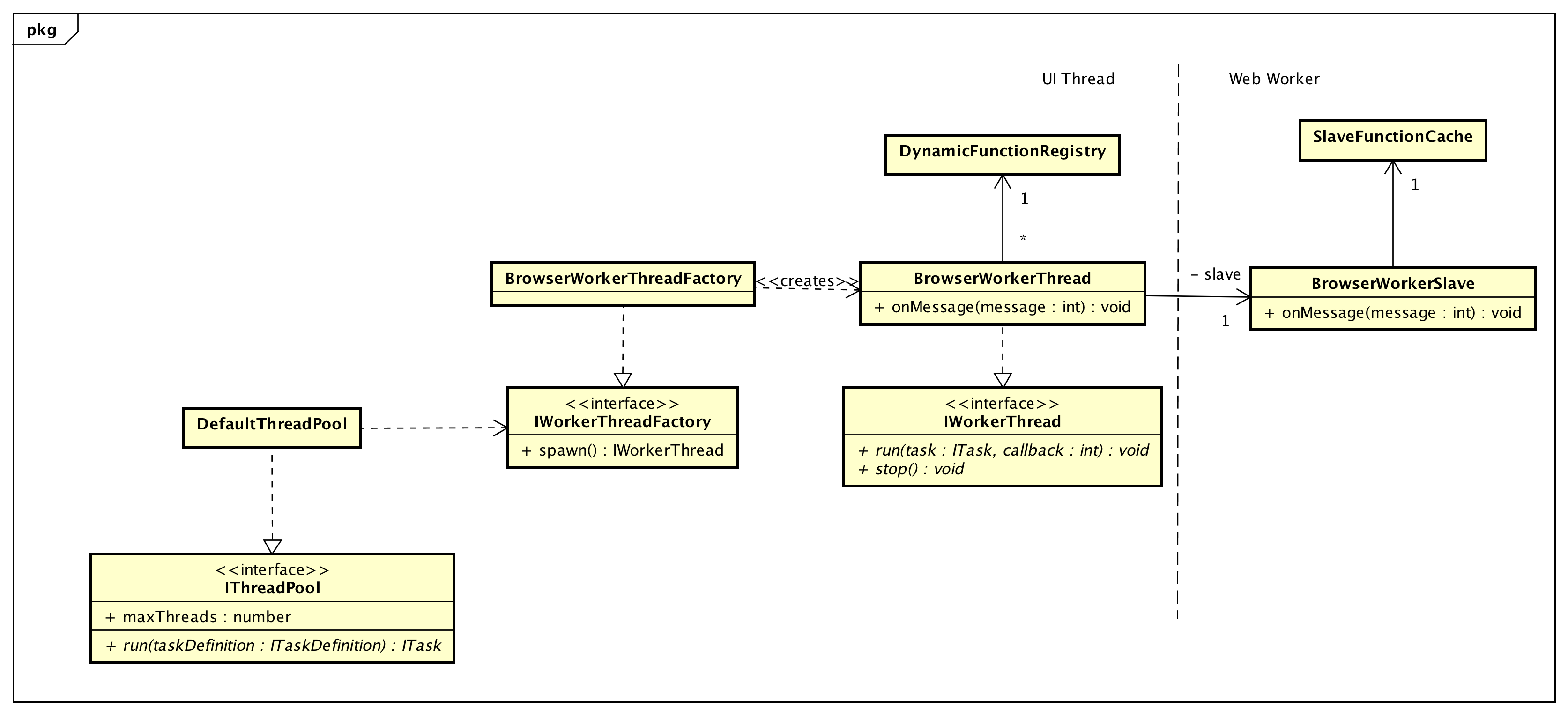
The thread pool provides the single run method for running a task on a background thread. The caller passes a serialized task definition. The thread pool chooses a background thread to run the task. In case there are no idle background threads available, then the thread pool queues the task. The DefaultThreadPool — implementation used by default — uses a fair FIFO Queue to store not yet scheduled tasks.
The IWorkerThreadFactory abstracts the actually used background worker implementation. The implementation may vary, depending on the runtime environment, e.g. Web Workers in the browser, child process in nodejs or any other. The factory is used by the IThreadPool to spawn new background workers.
Currently, only the BrowserWorkerThreadFactory exists that creates BrowserWorkerThreads.
Facade for the background worker that resists in the main thread. The facade allows to schedule a task on this particular background worker or to stop the worker.
Currently, only the BrowserWorkerThread implementation exists. The BrowserWorkerThread uses a Web Worker to perform the actual computation and acts as a facade to the BrowserWorkerSlave running on the Web Worker — not sharing any memory. The communication between BrowserWorkerThread and BrowserWorkerSlave is based on messaging.
The functions referenced in the task definition passed to run must be made available on the instance performing the computation, e.g., the BrowserWorkerSlave. The dynamic function registry stores the function definitions (serialized function) and assigns a unique id to each function. The unique id is used to identify scheduled function and allows to retrieve the function definition from the registry.
Stores all known functions for this worker slave instance. The worker uses the cache to resolve a function — given the unique function id. If the function id does not yet exist, then the function is requested from the BrowserWorkerThread, that uses the DynamicFunctionRegistry to retrieve the definition. The function is then stored in the cache for subsequent use. Storing the functions for later use has the advantage that JIT optimizations do not need to be performed every time the same function is scheduled onto the same background worker.