Difference between in_place and out_of_place #261
Comments
|
I'm sorry, I still don't understand why the offset is added to the in_place operation, could you give me a more detailed explanation, I didn't find the exact reason in the docs. As an example, when I was doing the scatter test, I realized that if in_place didn't add an offset, I would get different results, so I was wondering why the in_place operation needed an offset Looking forward to your reply, thanks! |
|
The offset depends on the collective used; see https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html. Broadcast, Reduce, and AllReduce operate on complete buffers for both input and output, so no offset is used. Allgather's input on each rank is smaller than the complete (output) buffer, and ReduceScatter's output on each rank is smaller than the complete (input) buffer. When you want NCCL to operate in-place (without having to allocate separate buffers for input and output), the address of the "sub-buffer" (input for AllGather, output for ReduceScatter) needs to be at a specific offset within the complete buffer for the algorithm to work correctly (the offset will be different for each rank). |
|
Do you mean that when collective is not running with a full buffer, the offset must be added in order to run correctly, and that if the offset is not added it will result in a performance degradation? Can you explain this in detail using Scatter as an example? Regarding the Scatter use case the offset calculation is as follows: void ScatterGetCollByteCount(size_t *sendcount, size_t *recvcount, size_t *paramcount, size_t *sendInplaceOffset, size_t *recvInplaceOffset, size_t count, int nranks) { |
|
Let me explain one more time. "in place" is a special case that may require additional considerations to work correctly. What makes it special is that the input buffer and the output buffer overlap (depending on the collective operation, they are either the same or one is a part of the other). Every collective will work just fine "out of place", i.e., when the input and output buffers are completely separate memory regions; there are no offsets or anything else of that sort to consider then. Implementation-wise "out of place" is generally simpler/more flexible; e.g., a collective operation is free to use the output buffer during its execution as a temporary storage for partial results, since its old content is irrelevant/discarded anyway. Because with "in place" the input and output overlap, the collective operation may need to be implemented differently, making sure that for the overlapping region it reads the input data before overwriting it with any output. In particular, NCCL requires that, if the buffers overlap, they do so in a very predictable, "natural" way. For example, imagine that you have an array of 2048 floats, but only the first 1024 contain a valid input. Now consider the following calls: The first call is out-of-place: the input and output buffers are non-overlapping. Because for the AllReduce operation the size of the input and output are the same, NCCL requires that, for in-place operation, the overlap is complete: the address of the input and output buffers must be the same. That's what the second call does. Now look at the third one: here there's a partial overlap -- the second half of the input buffer is also the first half of the output buffer. That's not supported -- you are likely to get a corrupted result. You asked about Scatter. Truth be told, it's not the best example, because for this collective only one rank contains the input while all the other ranks are output-only. In fact, NCCL doesn't even have a native Scatter operation -- nccl-tests implement it using (for Scatter, the input would be on only one rank -- the root -- but the output is the same for both operations) So for out-of-place variant those |
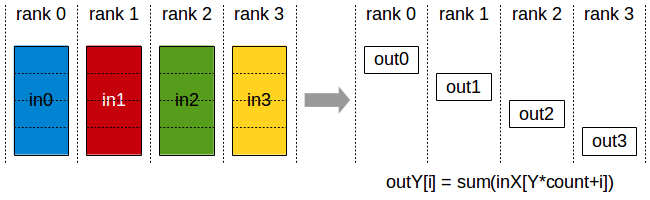
I found that there are two test patterns, one for in_place and one for out_of_place, what is the difference between these two, I also found that I need to add an offset when using in_place, why do I need to do that?
The text was updated successfully, but these errors were encountered: