This directory contains notebooks that can be used to train a reward model, and then fine-tune the LLM using Reinforcement Learning. For a detailed overview of Reward Modeling and RLHF, refer to:

- rewardModelTraining.ipynb : This notebook takes in user preference data as input and trains a model of choice to output scaler reward.
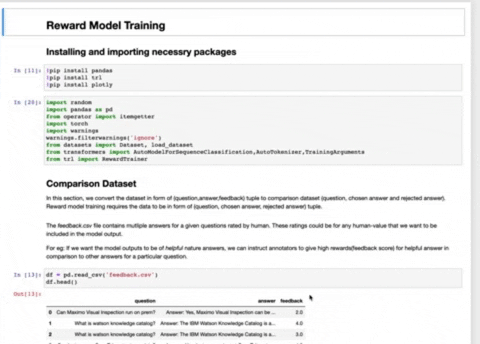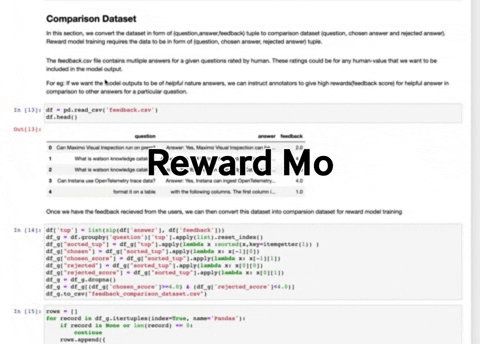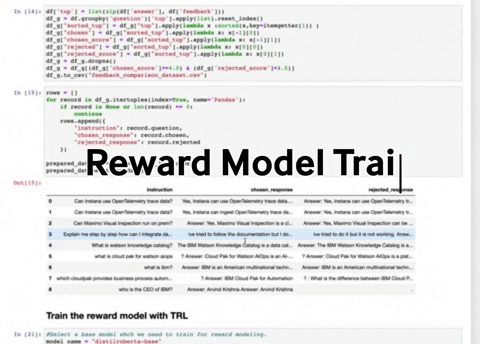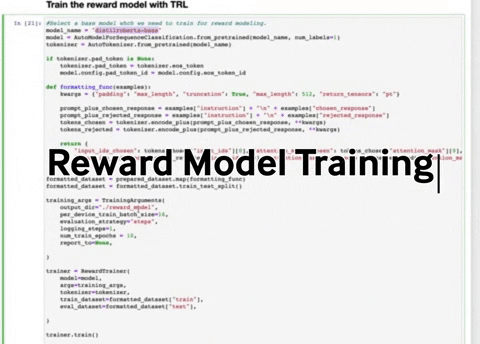
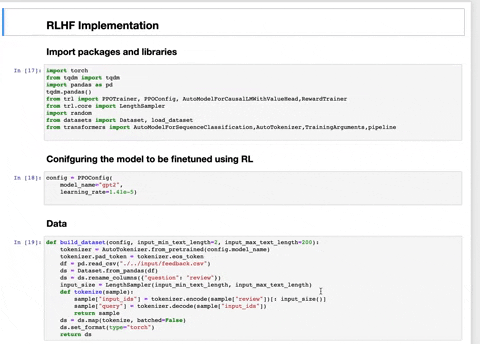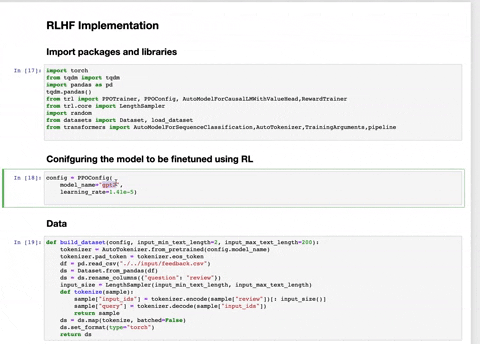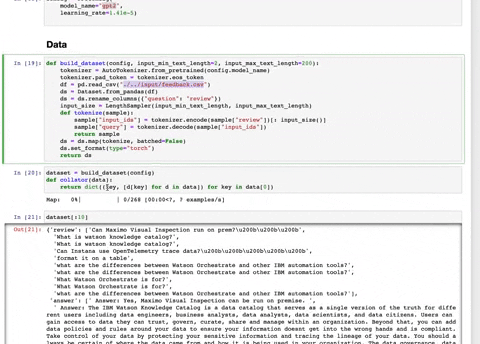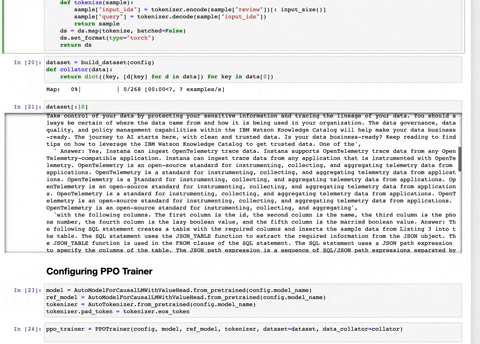
- RLHFImplementation.ipynb : This notebook takes a SFT LLM, a reward model and data as input. It then finetunes the LLM using PPO.