浅析浏览器缓存 #1
Comments
格式上的一个建议,中英文之间可以用空格隔开,如果英文指代为一些关键字,可以加粗标识。 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
格式上的一个建议,中英文之间可以用空格隔开,如果英文指代为一些关键字,可以加粗标识。 |
浅析浏览器缓存
众所周知,提高前端网页性能的一个很重要的一点就是减少HTTP请求。所以尽最大可能的缓存资源,可以显著提高网站的加载速度。浏览器缓存主要有两个概念,强缓存与协商缓存,强缓存通俗理解就是,我第一次打开一个网页,向服务器发送了一个HTTP请求,服务器把资源给我的同时,通过一些响应头(如Expries和Cache-Control:max-age=36000)告诉我强制把资源缓存到本地,所以下一次直接在本地读取资源,而不是再向服务器端发送请求!协商缓存,是用户在请求资源后,浏览器返回资源,同时会返回一些与这个资源相关的信息,如Last-Modified和ETag响应头,下次用户再请求资源的时候,会与服务器进行协商,判断资源是否更新,如果更新则重新从服务端拉取数据,否则直接采用浏览器缓存的资源!
Expries与Cache-Control(强缓存)
在HTTP1.0时代,控制浏览器缓存主要有两种方式,expries和pargam。
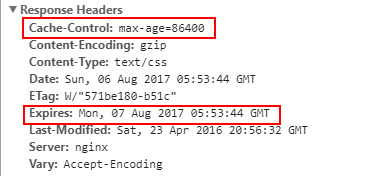
1.expries是用来设置过期时间,可以控制文件缓存的失效日期,设置为0效果等于不缓存,而且expries设置的失效时间是一个固定的时间,不是相对的时间。比如到哪年哪月失效。注意:expries设置的时间是服务器端的时间,所以如果客户端的时间与服务器端的时间不一致,那么可能这个expries这个属性就失效了。因此,expries有时候并不是很准确,HTTP1.1推出了Cache-Control来解决时间误差问题,所以现在之所以还在使用expries这个属性主要就是为了向下兼容。
2.pargam是设置禁用缓存,比如设置Pargam: no-cache,则不允许缓存。这个属性的优先级比较高,如果同时存在expries,则expries设置的属性失效,浏览器不会缓存资源!
3.由于expries是以服务器端的时间为准,所以HTTP1.1引入了Cache-Control,Cache-Control与expries的作用一致,都是设置资源的过期时间,但是Cache-Control设置的是一个相对时间,比如Cache-Control:max-age=3600,所以不会存在服务器与客户端时间不一致导致缓存失败的问题。
如图
很多时候expries和Cache-Control是同时存在的,既然他俩的作用是一样的,那肯定会有一个优先级,根据规范,如果他俩同时存在,则Cache-Control的优先级更高!以Cache-Control设置的为准!也就是说优先级从高到低分别是 Pragma -> Cache-Control -> Expires 。如果有缓存,且缓存没有过期,则直接从缓存中获取资源,不会向服务器发送请求,并返回状态码200 (from cache)。
Cache-Control可在请求头中使用的参考属性如下:
Cache-Control可在响应求头中使用的参考属性如下:
Last-Modified与If-Modified-Since(协商缓存)
当我们打开一个网页后,可以看一下他的响应头。可以看到这个Last-Modified属性,代表这次资源最后一次更新是2017年6月4号,然后状态码是200 OK。


然后我们F5刷新一下这个网页。可以看到,我们的请求头中多了If-Modified-Since这个字段,这个字段是为了对比服务器端的资源是否发生了改变,如果两次时间相等,则说明资源没有发生变化,代表可以直接使用缓存的资源,那么浏览器就不需要重新下载资源,状态码返回304 Not Modified.
现在我们设想一下这个问题,由于之前的字段设置的时间单位最小只能精确到秒,如果服务器端的资源在1s内发生了多次修改怎么办?显然这个字段还存在问题。
ETag与If-None-Match(协商缓存)
还是我们刚才的网页,我们可以看到,第一次请求这个资源的时候,响应头里不仅有Last-Modified,而且还有一个ETag响应头,而且是一个字符串,这个ETag,是服务器端对该资源的一个标识符,所以下一次请求的时候,请求头中就会有If-None-Match,向服务器端进行匹配,如果ETag与If-None-Match的字符串一致,则代表资源没有被修改。可以直接从缓存中获取!

注意,If-None-Match与If-Modified-Since同时存在的时候,以If-None-Match为准,因为If-None-Match的精确度更高!
用户行为控制缓存
可以参考网上的这张图

总结
整个浏览器请求与缓存相关的流程可以参考这两张图


浏览器第一次请求:
浏览器后续请求:
参考资料
1.MDN
2.浏览器缓存机制浅析
3.浏览器缓存
The text was updated successfully, but these errors were encountered: