Mimicking leaderboard test
Doing some real work this time:
- Hyper-parameter searching
- Feature elimination
- Feature vizualisation
First setting up the plotting defaults and numpy.
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
plt.rcParams['figure.figsize'] = 6, 4.5
plt.rcParams['axes.grid'] = True
plt.gray()
As before, loading the data. But, now there's more data to load.
cd ..
import train
import json
import imp
settings = json.load(open('SETTINGS.json', 'r'))
settings['FEATURES']
['ica_feat_var_',
'ica_feat_cov_',
'ica_feat_corrcoef_',
'ica_feat_pib_',
'ica_feat_xcorr_',
'ica_feat_psd_',
'ica_feat_psd_logf_',
'ica_feat_coher_',
'ica_feat_coher_logf_',
'raw_feat_var_',
'raw_feat_cov_',
'raw_feat_corrcoef_',
'raw_feat_pib_',
'raw_feat_xcorr_',
'raw_feat_psd_',
'raw_feat_psd_logf_',
'raw_feat_coher_',
'raw_feat_coher_logf_']
# reducing no. of features for faster prototyping
settings['FEATURES'] = settings['FEATURES'][1:2]
data = train.get_data(settings['FEATURES'])
!free -m
total used free shared buffers cached
Mem: 11933 8451 3481 62 31 3156
-/+ buffers/cache: 5263 6669
Swap: 12287 1052 11235
The leaderboard test is apparently a combined ROC AUC over all of the test sets, although I can't find the Forum post about this. This shouldn't be too hard to mimic, and what we want is a function that will run a single batch of cross-validation given a model and return results for the various folds.
# getting a set of the subjects involved
subjects = set(list(data.values())[0].keys())
print(subjects)
{'Patient_1', 'Dog_2', 'Dog_5', 'Dog_3', 'Dog_1', 'Dog_4', 'Patient_2'}
So the easiest way to do this will be to use the cross_val_score method of
scikit-learn on a training set for each subject.
It would be best to arrange this as a function so that it can be called with a
map for parallelism later, if required.
The first part is a function that will take a model and a subject and return a set of probabilities along with the true labels.
import sklearn.preprocessing
import sklearn.pipeline
import sklearn.ensemble
import sklearn.cross_validation
from train import utils
scaler = sklearn.preprocessing.StandardScaler()
forest = sklearn.ensemble.RandomForestClassifier()
model = sklearn.pipeline.Pipeline([('scl',scaler),('clf',forest)])
def subjpredictions(subject,model,data):
X,y = utils.build_training(subject,list(data.keys()),data)
cv = sklearn.cross_validation.StratifiedShuffleSplit(y)
predictions = []
labels = []
for train,test in cv:
model.fit(X[train],y[train])
predictions.append(model.predict_proba(X[test]))
labels.append(y[test])
predictions = np.vstack(predictions)[:,1]
labels = np.hstack(labels)
return predictions,labels
p,l = subjpredictions(list(subjects)[0],model,data)
import sklearn.metrics
sklearn.metrics.roc_auc_score(l,p)
0.94699999999999995
That seems a little high... Especially as we're only running this with one feature, and default settings.
fpr,tpr,thresholds = sklearn.metrics.roc_curve(l,p)
plt.plot(fpr,tpr)
[<matplotlib.lines.Line2D at 0x7f1fc12746d8>]
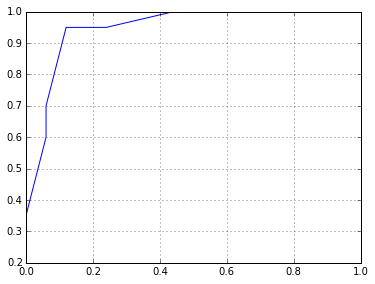
So the performance is artificially high. To check this isn't real, will use this feature and settings on the test data and submit it.
features = list(data.keys())
%%time
predictiondict = {}
for subj in subjects:
# training step
X,y = utils.build_training(subj,features,data)
model.fit(X,y)
# prediction step
X,segments = utils.build_test(subj,features,data)
predictions = model.predict_proba(X)
for segment,prediction in zip(segments,predictions):
predictiondict[segment] = prediction
CPU times: user 373 ms, sys: 26.7 ms, total: 400 ms
Wall time: 399 ms
import csv
with open("output/protosubmission.csv","w") as f:
c = csv.writer(f)
c.writerow(['clip','preictal'])
for seg in predictiondict.keys():
c.writerow([seg,"%s"%predictiondict[seg][-1]])
Scored 0.52433, so no, it's not some magical classifier.
Anyway, at least that tells us what score this test we're building should be returning, in this case. Trying to replicate by iterating the above function over all subjects.
pls = list(map(lambda s: subjpredictions(s,model,data), subjects))
# this line is going to be problematic
p,l = list(map(np.hstack,list(zip(*pls))))
p.shape
(4100,)
l.shape
(4100,)
sklearn.metrics.roc_auc_score(l,p)
0.9199140350877193
fpr,tpr,thresholds = sklearn.metrics.roc_curve(l,p)
plt.plot(fpr,tpr)
[<matplotlib.lines.Line2D at 0x7f2028f15198>]
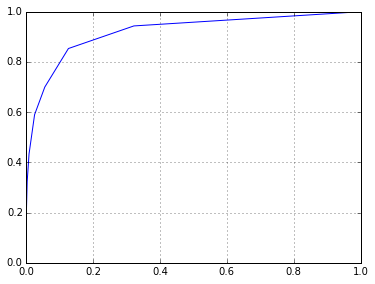
sklearn.metrics.accuracy_score(l,list(map(int,p)))
0.92731707317073175
This doesn't make much sense, there must be an error above that's causing the classifier to be much more accurate than possible - causing massive overfitting.
Ok, so it turns out these problems are probably occurring because I'm not
dealing with the unbalanced classes in all these datasets.
In each of the subject training sets there are more zeros than ones, and that
was something I was going to sort out below using Bayes theorem.
However, there is an input to many of scikit-learn's functions called
sample_weight to solve this problem because obviously it comes up all the
time.
Repeating the above with the proper weightings:
def subjpredictions(subject,model,data):
X,y = utils.build_training(subject,list(data.keys()),data)
cv = sklearn.cross_validation.StratifiedShuffleSplit(y)
predictions = []
labels = []
allweights = []
for train,test in cv:
# calculate weights
weight = len(y[train])/sum(y[train])
weights = np.array([weight if i == 1 else 1 for i in y[train]])
model.fit(X[train],y[train],clf__sample_weight=weights)
predictions.append(model.predict_proba(X[test]))
weight = len(y[test])/sum(y[test])
weights = np.array([weight if i == 1 else 1 for i in y[test]])
allweights.append(weights)
labels.append(y[test])
predictions = np.vstack(predictions)[:,1]
labels = np.hstack(labels)
weights = np.hstack(allweights)
return predictions,labels,weights
plws = list(map(lambda s: subjpredictions(s,model,data), subjects))
p,l,w = list(map(np.hstack,list(zip(*plws))))
sklearn.metrics.roc_auc_score(l,p,sample_weight=w)
0.92410537227214373
fpr,tpr,thresholds = sklearn.metrics.roc_curve(l,p,sample_weight=w)
plt.plot(fpr,tpr)
[<matplotlib.lines.Line2D at 0x7f20290dec50>]
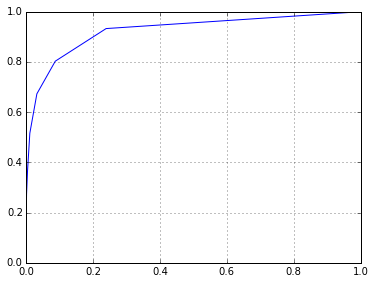
Looks like that hasn't fixed the problem. Unfortunately, I don't know why.
Checking what effect this has had on the leaderboard position:
predictiondict = {}
for subj in subjects:
# training step
X,y = utils.build_training(subj,features,data)
# weights
weight = len(y)/sum(y)
weights = np.array([weight if i == 1 else 1 for i in y])
model.fit(X,y,clf__sample_weight=weights)
# prediction step
X,segments = utils.build_test(subj,features,data)
predictions = model.predict_proba(X)
for segment,prediction in zip(segments,predictions):
predictiondict[segment] = prediction
with open("output/protosubmission.csv","w") as f:
c = csv.writer(f)
c.writerow(['clip','preictal'])
for seg in predictiondict.keys():
c.writerow([seg,"%s"%predictiondict[seg][-1]])
Ok, submitted and it worked. Got a score of 0.68118 and moved 93 positions up the leaderboard. Still, haven't succeeded in replicating their test though.
Could compare our performance in the AUC score to a dummy classifier:
import sklearn.dummy
dmy = sklearn.dummy.DummyClassifier(strategy="most_frequent")
dummy = sklearn.pipeline.Pipeline([('scl',scaler),('clf',dmy)])
plws = list(map(lambda s: subjpredictions(s,dummy,data), subjects))
p,l,w = list(map(np.hstack,list(zip(*plws))))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-152-c7686c94e4e5> in <module>()
----> 1 plws = list(map(lambda s: subjpredictions(s,dummy,data), subjects))
2 p,l,w = list(map(np.hstack,list(zip(*plws))))
<ipython-input-152-c7686c94e4e5> in <lambda>(s)
----> 1 plws = list(map(lambda s: subjpredictions(s,dummy,data), subjects))
2 p,l,w = list(map(np.hstack,list(zip(*plws))))
<ipython-input-123-fb70372cd195> in subjpredictions(subject, model, data)
9 weight = len(y[train])/sum(y[train])
10 weights = np.array([weight if i == 1 else 1 for i in y[train]])
---> 11 model.fit(X[train],y[train],clf__sample_weight=weights)
12 predictions.append(model.predict_proba(X[test]))
13 weight = len(y[test])/sum(y[test])
/home/gavin/.local/lib/python3.4/site-packages/sklearn/pipeline.py in fit(self, X, y, **fit_params)
128 """
129 Xt, fit_params = self._pre_transform(X, y, **fit_params)
--> 130 self.steps[-1][-1].fit(Xt, y, **fit_params)
131 return self
132
TypeError: fit() got an unexpected keyword argument 'sample_weight'
def subjpredictions(subject,model,data):
X,y = utils.build_training(subject,list(data.keys()),data)
cv = sklearn.cross_validation.StratifiedShuffleSplit(y)
predictions = []
labels = []
allweights = []
for train,test in cv:
# calculate weights
try:
weight = len(y[train])/sum(y[train])
weights = np.array([weight if i == 1 else 1 for i in y[train]])
model.fit(X[train],y[train],clf__sample_weight=weights)
except TypeError:
# model doesn't support weights
model.fit(X[train],y[train])
predictions.append(model.predict_proba(X[test]))
weight = len(y[test])/sum(y[test])
weights = np.array([weight if i == 1 else 1 for i in y[test]])
allweights.append(weights)
labels.append(y[test])
predictions = np.vstack(predictions)[:,1]
labels = np.hstack(labels)
weights = np.hstack(allweights)
return predictions,labels,weights
plws = list(map(lambda s: subjpredictions(s,dummy,data), subjects))
p,l,w = list(map(np.hstack,list(zip(*plws))))
sklearn.metrics.roc_auc_score(l,p,sample_weight=w)
0.5
Wait, no that obviously won't work.
Undersampling the majority class instead.
plws = list(map(lambda s: subjpredictions(s,model,data), subjects))
p,l,w = list(map(np.hstack,list(zip(*plws))))
import random
k = sum(l)
samples = random.sample([x for x,i in list(enumerate(l == 0)) if i==True],k) + [x for x,i in list(enumerate(l == 1)) if i==True]
sklearn.metrics.roc_auc_score(l[samples],p[samples],sample_weight=w[samples])
0.92460454994192809
Well, that hasn't worked either.
Checking my sampling has actually made sense:
sum(l[samples])/len(l[samples])
0.5
Yeah, sampling has worked, classifier is still just performing too well.
Will have to think about this, can't think of anything else to fix this with.