Bem-vindo ao minicurso de redis!
A ideia é te dar um roadmap e explicação sobre o básico do banco de dados mais quente do mercado. Iremos abordar sobre sua arquitetura geral, tipos de dados, operações básicas, pesistência e como setar seu próprio cluster redis ®.
Esse minicurso não vai esgotar tudo o que se têm para dizer sobre redis, então recomendo fortemente que
você busque saber mais por si mesmo e explore esse mundo muito foda de NoSQL. Bons lugares para se começar: documentação oficial, código fonte e wikipedia. Espero que goste :)
Mas afinal, o que é o redis?
Ele é um banco de dados in-memory com pesistência opcional bem simples (yet powerful). Você pode pensar nele como um servidor de estrutura de dados, isso significa que:
O redis provê acesso a estruturas de dados mutáveis através de um conjunto de comandos que são enviados usando um modelo cliente-servidor. Dessa forma, diferentes processos podem realizar pesquisas e modificações nas mesmas estruturas de dados de forma compartilhada. [1]
Por conta disso ele é MUITO utilizado como servidor de cache [2] [3], comunicação entre serviços [4] e muito mais.
Vou ser sincero, não quero perder tempo com isso, siga as instruções de instalação e seja feliz.
Durante o minicurso irei utilizar docker, se você ainda não têm instalado vai lá no docker.docs e instala. Voltou? Ótimo! Para rodar o redis basta executar:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latestEsse comando vai criar um único container de docker e expor duas portas:
6379porta padrão do servidor redis;8001porta para o Redis Insight ® ;
Vamos explorar o Redis Insight ® mais pro final do minicurso, como somos try hard iremos utilizar majoritariamente a linha de comando. Chega de papo, bora lá!
Para se conectar no REPL do servidor redis basta rodar:
docker exec -it redis-stack redis-cliINFO
redis-clié a ferramenta de linha de comando do redis. Você pode saber mais sobre ela aqui
Como eu disse, redis é um servidor de estrutura de dados, essas estruturas são definidas como data types, vamos passar por cima das principais, mas antes disso um adendo: as operações nas estruturas do redis são realizadas através de commands; não vai ser possível mostrar todos os commands de cada estrutura então se ficar curioso poderá buscar mais sobre cada uma na documentação de comandos:
A forma mais simples de estrutura de dados no redis é o chave-valor. Chaves são strings e valores também, dentro do REPL digite:
SET melhor-aula nosqlO comando SET "seta" uma chave com um valor associado, nesse caso a chave melhor-aula está associada com o valor nosql. Para acessar o valor basta digitar:
GET melhor-aula
# Resultado -> "nosql"WARNING Se rodarmos
SETquando uma chave já existe, seu valor anterior é sobrescrito. Para evitar esse comportamento é necessário passar o parâmetronxno final do comando.
E você pode usar qualquer string como valor (com tamanho de até 512MB), até mesmo imagens!
Imagine que está desenvolvendo uma rede social com altos requerimentos de escalabilidade e precisa guardar quantos views um post possui, você provavelmente estará usando vários serviços, espalhados no mundo todo. Como garantir que diferentes serviços compartilhem esse dado?
Yup, você acertou, com redis;
O comando INCR associa uma chave a um valor numérico, e toda vez que INCR é chamado com a chave ele incrementa +1 no valor atual, por exemplo:
INCR user:post-1:views Execute várias vezes, você verá o valor incrementando.
INCRBY user:post-1:views 42Incrementa o valor +42, (você também pode incrementar números negativos).
Listas em redis são listas ligadas com ponteiros para o início e final da fila, isso significa que operações de pop e push são feitas em O(1). O seu trade-off são operações que utilizam índices, pois cria a necessidade de percorrer cada elemento da lista. O redis fornece alternativas caso necessitemos utilizar indíces mas isso vai ficar pra depois :)
Para inserirmos um novo elemento em uma lista utilizamos o comando LPUSH ou RPUSH, por exemplo:
LPUSH fila-espera:cafe Alice Bob Joe
LPUSHinsere um novo elemento no início da lista (head) eRPUSHfaz o mesmo mas no final da fila (tail).
Note que não existe um comando para criar uma lista, simplesmente inserimos um dado. Se a lista existe um novo dado é incluído, se não existe nosso querido redis se responsabiliza por criar; isso se aplica para todo data type :).
Além disso, LPUSH e RPUSH são comandos variáticos o que significa que somos livres para inserir um ou mais elementos de uma só vez.
Para removermos um elemento da lista utilizamos:
LPOP fila-espera:cafe A mesma lógica de pushs se aplica aqui:
LPOPremove elementos no início eRPOPno final.
Para verificarmos elementos de uma lista utlizamos LRANGE (sim L é usando tanto como left quanto list, that's life).
LRANGE fila-espera:cafe 0 3O comando acima busca os 4 primeiros elementos da lista, o primeiro argumento é o índice do início de nosso range e o segundo é o final do range. Também podemos utilizar números negativos, então o redis começa a contar de "trás pra frente": -1 é o último elemento, -2 o penúltimo e assim por diante.
LRANGE fila-espera:cafe 0 -1
# Busca todos os elementos da listaUm caso de uso comum para lista em redis é manter o n últimos elementos de alguma coisa. Tweets por exemplo [5]. O que queremos é uma capped collection nesse caso uma capped list (literalmente lista limitada), utilizaremos LTRIM
para fazer isso.
LTRIM é muito parecido com LRANGE com a única diferença de que LRANGE é feito para consultas (logo não modifica a lista) e LTRIM literalmente apara tudo o que não estiver dentro do range, exemplo:
LPUSH last:3:custumers Chris Ana Anthony
LRANGE last:3:custumers 0 2
LPUSH last:3:custumers Paul
LTRIM last:3:custumers 0 2
# cuidado com erros off-by-one
LRANGE last:3:custumers 0 2Seguindo essa sequencia vemos que Chris é "aparado" da lista visto que é o 4° mais recente.
Sets (conjuntos) é uma coleção não ordenada de strings únicas. Elas são muito úteis para representar pertencimento de um item a um conjunto, valores únicos, etc.
Vamos adicionar um novo item no set com:
SADD nosql:students Joaozinho MariazinhaPara checarmos pertencimento utilizamos:
SISMEMBER nosql:students Joaozinho
# (integer) 1
SISMEMBER nosql:students Jack
# (integer) 0Podemos também fazer operações de intersecção!
SADD bd-2:students Joaozinho Caio
SINTER nosql:students bd-2:students
# 1) "Joaozinho"E cardinalidade:
SCARD nosql:students
# (integer) 2Para removermos um elemento:
SREM nosql:students Joaozinho
SMEMBERS nosql:students # Lista todos os elementos da listaPara maioria das operações a complexidade é O(1), contudo para sets grandes deve-se utilizar o comando SMEMBERS com cuidado, já que ele possui complexidade O(n).
Hashes em redis funcionam como uma coleção de strings, podemos usá-los para representar objetos básicos dentre outros dados.
HSET aluno:1 nome Jacob curso "Sistemas de informacao" hobbie "virar lobisomem"
HGETALL aluno:1
# 1) "nome"
# 2) "Jacob"
# 3) "curso"
# 4) "Sistemas de informacao"
# 5) "hobbie"
# 6) "virar lobisomem"
HGET aluno:1 nome
# "Jacob"NOTE: Você deve ter reparado que utilizamos ':' para separar tokens nos nomes, isso é apenas uma convenção. Nomes e chaves devem ter eles mesmos significado. Por exemplo, 'aluno:1' provavelmente é um aluno com id 1, o redis não faz a mínima ideia desse id, portanto sua aplicação deve se responsbilizar por manter um padrão coerente e que não sobrescreva incorretamente dados anteriores.
Também podemos manter contadores em nossos "objetos"
HINCRBY aluno:1 faltas 1
HGETALL aluno:1
# 1) "nome"
# 2) "Jacob"
# 3) "curso"
# 4) "Sistemas de informacao"
# 5) "hobbie"
# 6) "virar lobisomem"
# 7) "faltas"
# 8) "1"Lembra quando eu disse que o redis fornecia uma estrutura de dados para usar índices. Pois bem, voilà.
Sorted sets são como um mix entre Sets e Hashes, são formados por
elementos não-repetíveis, porém agora cada elemento é associado a um float point
chamado score como um hash. Este score é utilizado para comparar valores, então se:
A > B logo A.score > B.score. Um fator interessante é que os elementos são guardados
já ordenados, então buscas ordenadas não custam tanto.
Para incluir novos elementos:
ZADD brasileirao:tabela 0 Botafogo 1 Palmeiras 3 Fortaleza 4 Flamengo
ZRANGE brasileirao:tabela 0 -1
# 1) "Botafogo"
# 2) "Palmeiras"
# 3) "Fortaleza"
# 4) "Flamengo"
ZREVRANGE brasileirao:tabela 0 -1
# 1) "Flamengo"
# 2) "Fortaleza"
# 3) "Palmeiras"
# 4) "Botafogo"Podemos passar o argumento WITHSCORES nos comandos de range para também
devolver os ranges:
ZRANGE brasileirao:tabela 0 -1 WITHSCORES
# 1) "Botafogo"
# 2) "0"
# 3) "Palmeiras"
# 4) "1"
# 5) "Fortaleza"
# 6) "3"
# 7) "Flamengo"
# 8) "4"Podemos realizar comando em scores:
ZRANGEBYSCORE brasileirao:tabela -inf 3 # busca todos os elementos com score entre -infinto e 3.
# 1) "Botafogo"
# 2) "Palmeiras"
# 3) "Fortaleza"Também podemos buscar o score de um valor com:
ZRANK brasileirao:tabela Palmeiras
# (integer) 1Lembra quando eu disse que redis possui pesistência opcional? Vamos ver como configurá-la agora! O Redis tem 4 tipos
de persistência:
- RDB (Redis Database): Snapshots que são realizados em intervalos específicos;
- AOF (Append Only File): Arquivo de log de toda operação de escrita, que podem ser replicadas quando o servidor reinicia, reconstruindo seu estado original.
- Sem persistência: Autoexplicativo né. Se o servidor cair não tem jeito de recuperar os dados.
- RDB + AOF: Combinação das estratégias de logging e snapshotting
Você pode ler mais sobre seus trade-offs aqui.
Redis é single-threaded então como podemos fazer o snapshot sem bloquear a thread e perder operações? O processo realiza um fork() e esse fork() que realiza essa operação, enquanto o processo pai continua ativo recebendo requisições.[6]
Se você reparou, na raíz do projeto existe um arquivo chamado redis.conf, lá
podemos configurar nosso servidor redis. Ele também possui comentários muito
úteis que os próprios desenvolvedores disponibilizaram para que a comunidade entenda melhor cada parâmetro e seu funcionamento interno.
Abra-o e pesquise por SNAPSHOTTING essa seção nos fornece toda a configuração relacionada ao RDB, descomente a linha 440 e a mude para save 5 1. Ela
significa que a cada 5s iremos realizar um snapshot se ao menos uma key mudou.
WARNING Essa é uma quantidade excessiva de snapshotting, ela é apenas para experimentarmos mais facilmente.
Bacana, a partir de agora vamos utilizar docker compose, ele é uma extensão de docker que nos permite, declarativamente, configurar
múltiplos containers. Se não o tiver basta seguir a [documentação].
Pare a instância que estavamos rodando com docker container stop redis-stack e
utilize docker compose up e acesse o novo container com docker compose exec -it redis redis-cli. Para nos certificarmos que estamos com a nova configuração rode:
CONFIG GET save
# Resposta esperada
# 1) "save"
# 2) "5 1"Cool, crie uma nova chave e espere 5s. Em outro terminal rode:
docker compose cp redis:/data/dump.rdb ./dump.rdbEsse comando copia o arquivo de dump para nosso diretório atual. Com ele podemos restaurar nossos dados caso o servidor caia.
Agora vamos parar o container e apagar sua imagem com:
docker stop redis
docker rm redisAgora restaure a imagem com docker compose up, copie o arquivo para dentro do container: docker cp ./dump.rdb redis:/data/dump.rdb e o reinicie com:
docker compose restartBasta entrar no container e verificar os dados que salvamos no dump :)
Um problema de snapshotting é que se o sevidor cair perdemos os dados que foram escritos depois do último snapshot, se não podemos perder nem um dado se quer devemos considerar utilizar AOF.
Para habilitá-lo vá em redis.conf e busque por APPEND ONLY MODE essa é a seção de configuração do AOF. Mude a linha appendonly no para appendonly yes.
Resete o servidor, o acesse e faça alguma operação de escrita.
Para recuperar o diretório de logs rode:
❯ docker compose cp redis:data/appendonlydir ./appendonlydirse vermos o conteúdo desse diretório com ls appendonlydir veremos que temos 3 arquivos, o que são eles:
appendonly.aof.1.base.rdb: É um snapshot de todo o banco no momento em que esse arquivo foi criado.appendonly.aof.1.incr.aof: Todos os comandos que alteraram o banco que foram rodados depois do snapshot.appendonly.aof.manifest: Gerencia os outros arquivos e garante a ordem em que devem ser executados.
Para saber mais sobre o assunto de persistência recomendo começar por [aqui] e [aqui].
Tudo o que vimos até agora acontece em uma instância de redis, manipulação de estruturas de dados e recuperação de dados. Mas e se quisermos garantir um downtime baixo com alta disponibilidade? Ou se precisamos aumentar o throughput? Ai que entra a distribuição.
Uma forma simples de aumentarmos o throughput é através da replicação. Dividimos nossas intâncias de redis em dois tipos: líder (master) e seguidores (slaves). Operações de escrita só podem ser realizadas no líder e este por sua vez replica os dados para seus seguidores. Dessa forma, tiramos a carga de leitura de um servidor e distribuimos entre os seguidores, enquanto o líder só se ocupa com as operações de escrita e replicação. Vamos ver isso funcionando.
Na pasta replication, execute o seguinte comando para iniciar o replica-set:
docker-compose upSimples não? Agora abra dois terminais e execute os comandos abaixo, um pra cada terminal:
docker exec -it redis-master redis-cli
docker exec -it redis-slave-1 redis-cli Tente escrever algo no redis-slave-1, vai dar erro, por quê? Como ele é um servidor de réplica
somente ações READ ONLY podem ser executadas. Ainda no redis-slave-1 rode:
GET melhor-aula
# (nil)Agora no servidor master rode SET melhor-aula nosql, se dermos GET em ambos os servidores o dado
melhor-aula estará disponível!
Replicação é legal mas ela possui alguns drawbacks:
- Muita dependencia do master;
- Não escala horizontalmente por que a escrita é "engargalada" pela master;
- Se algum nó cai o redis não se recupera sozinho
Uma das maneiras de resolver isso é com sentinelas
que nada mais são que outros processos que ficam "vigiando" nosso replica-set, ele cuida de todo sistema de eleição de líder,
notificação, etc. Não falaremos dele aqui por que o escritor perdeu 3 anos de vida útil tentando configurar Fique livre para estudar esse modelo :)
Outra forma é com clusterização, com ele o redis faz automagicamente um processo de sharding que nada mais é que separar sua base de dados entre os nós, ao invés de cada um ter uma cópia da base toda. Assim, novos nós podem ser adicionados e removidos da rede de forma a reorganizar os dados facilmente.
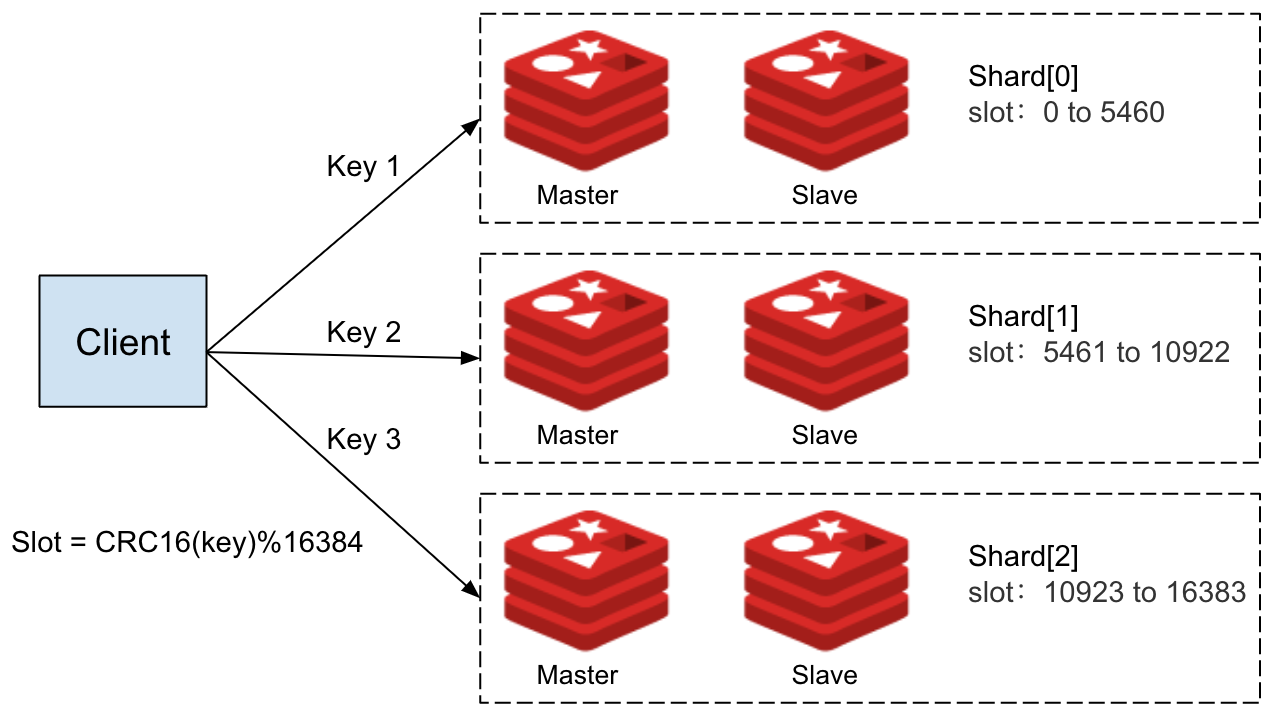
Para rodar as instâncias redis em sua máquina, vá para o diretório cluster e rode docker compose up.
Para iniciar o cluster, rode:
docker exec -it cluster-redis-node-1-1 redis-cli --cluster create \
redis-node-1:6379 \
redis-node-2:6379 \
redis-node-3:6379 \
redis-node-4:6379 \
redis-node-5:6379 \
redis-node-6:6379 \
--cluster-replicas 1Ele irá criar nosso cluster com os nodes passados com um fator de replicação de 2, o que significa que cada escrita deve ser replicada para pelo menos dois nós.
Conecte no primeiro nó com docker exec -it cluster-redis-node-1-1 redis-cli -c e rode:
SET key1 "value1"
SET key2 "value2"
SET key3 "value3"
SET key4 "value4"Para algumas chaves você deve ter recebido -> Redirect to slot <slot_number> located at <slot_host> antes do OK, isso significa que a chave que setamos não se encontra no node-1, porém se dermos GET em uma chave "movida" conseguimos, por quê?
Reparou no -c que passamos junto ao redis-cli? Ele torna o nosso redis client ciente que está em ambiente de cluster, se tentarmos acessar sem o -c iremos receber um (error) MOVED <slot_number> <slot_host>
Podemos consultar qual keyslot uma chave pertence com CLUSTER KEYSLOT <keyslot>, para sabermos quais nodes
pertencem ao nosso cluster podemos rodar: CLUSTER NODES.
Vamos adicionar um novo nó no cluster. Dentro do arquivo docker-compose.yml descomente o serviço redis-node-7 e execute: docker compose up redis-node-7
Agora acesse o nó 1 com docker exec -it cluster-redis-node-1-1 bash e rode redis-cli --cluster add-node redis-node-7:6379 redis-node-1:6379. Entrando no cliente redis com redis-cli podemos pesquisar pelos nós como explicado acima, e verificar que ele foi de fato aceito. Agora podemos redistribuir as chaves rodando: redis-cli --cluster rebalance redis-node-1:6379
Redis Insight é uma ferramenta web que nos permite interagir com o redis de forma intuitiva e prática. Eu sei eu sei, poderíamos estar usando ela desde o começo mas onde está a didática em não sofrer?
Para roda-lo basta descomentar o serviço de redis-insight no docker-compose e rodar: docker compose up redis-insight, ele estará exposto na porta 8001.
Por lá podemos cadastrar nossos nós do cluster e importar os dados que estão na raiz do diretório cluster.
Redis é uma tecnologia bem interessante, embora simples ela nos dá flexibilidade e performance para resolver problemas de escala no mundo real, sem dúvidas uma ótima carta na manga para qualquer desenvolvedor.
Espero que você tenha gostado desse mini-curso, se ele foi útil para você de alguma forma não esqueça de deixar uma estrelinha e compartilhar com os amigos. Até mais e accelerate, anon.