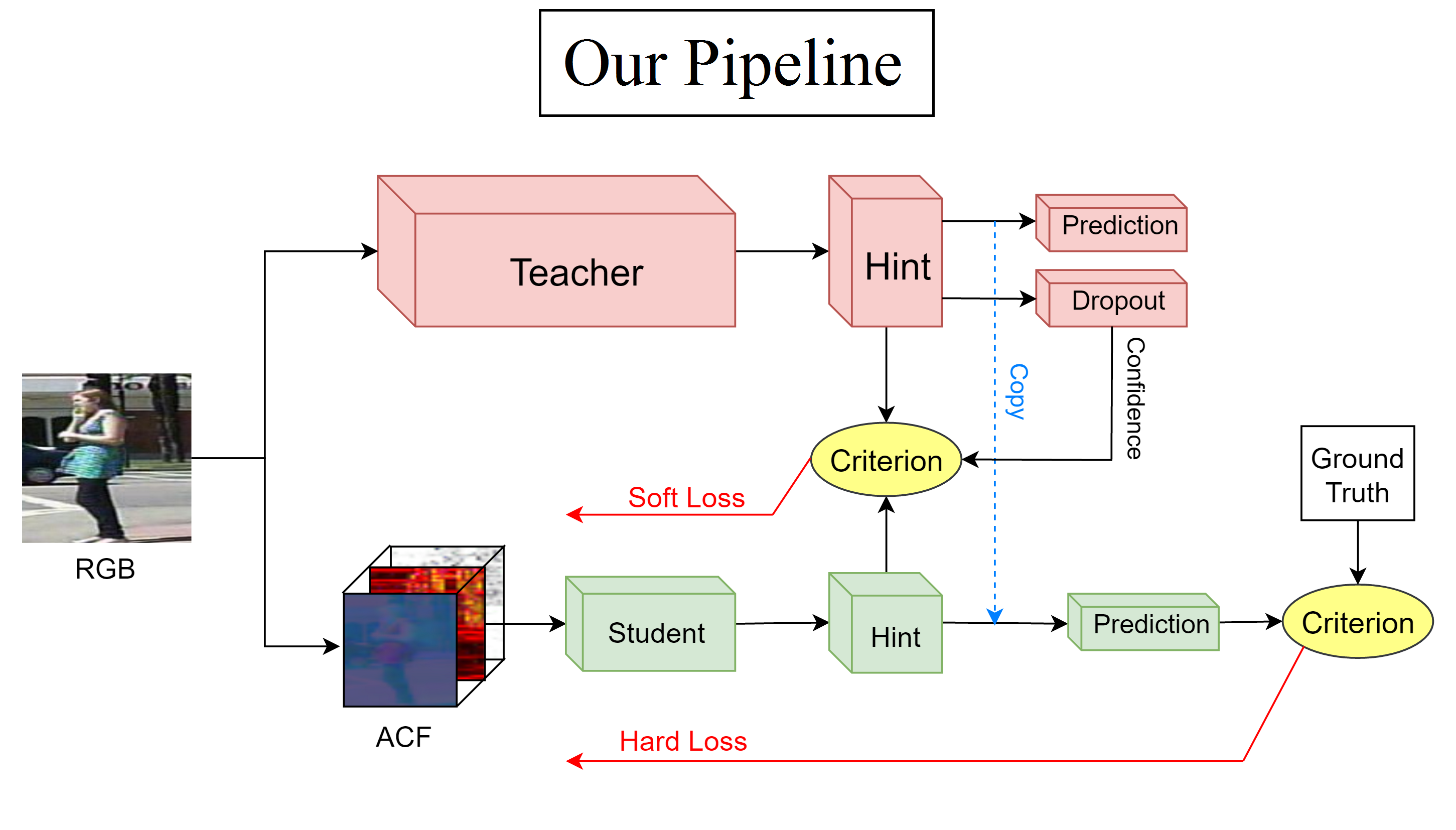
##Introduction We compress the pedestrian detection model from ResNet-200 (63 millions parameter) to our fixed channel ResNet-18 (0.157 million parameter). Our paper utilizes the idea of Knowledge Distillation with extra helps from model confidence and hint layer to achieve 400x compression with 4.9% log-average miss rate drop. For more detail, please refer to our arXiv paper and slides.
##Result Log-average miss rate on Caltech (lower is better)
| Model | Log-avg MR | #Parameters | Time (Titan X) | Memory |
|---|---|---|---|---|
| ResNet-200 | 17.5% | 63M | 24ms | 5377MB |
| ResNet-18 | 18.0% | 11M | 3ms | 937MB |
| ResNet-18-Thin | 20.3% | 2.8M | 3ms | 633MB |
| ResNet-18-Small | 22.4% | 0.157M | 3ms | 565MB |
| *Results are from the highest improvement method (Hint+Conf). |
##Demo

##Installation ###Training The networks were trained by torch-nnet-trainer. Please set up caltech10x dataset according to Hosang.
###Testing on TX1 Ideally, the dynamic library should work for TX1. However, if an issue occurs, please build SquareChnnlFltrs for region proposal and replace "libmonocular_objects_detection.so".
The input is a set of images from video (extract by convert.sh). Use "make forward" for building forward.cpp, and "make run --input($input) --output($output)" to forward the images.
##Citing our model If you found our model useful, please cite our paper:
@articles{ShenTrust2016,
title = {In Teacher We Trust: Learning Compressed Models for Pedestrian Detection},
author = {Shen, J., Vesdapunt, N., Boddeti, V.~N., Kitani, K.~M. and Osterwood, C.},
journal = {arXiv preprint, arXiv:1612.00478},
year = {2016}
}