-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Create 2024-10-11-subtlety-of-data-science.md
- Loading branch information
Showing
1 changed file
with
77 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,77 @@ | ||
| --- | ||
| title: "On the subtlety of data science" | ||
| layout: single | ||
| excerpt: "and how to reclaim it" | ||
| tags: [essay, data-science] | ||
| --- | ||
|
|
||
| Data science is subtle, it's really more art than science. Attempting to solve every problem in a perfectly "scientific" way is like painting by numbers - we lose the subtle shades and depth that make the art interesting. | ||
|
|
||
| For me, data science appeals because it provides me an opportunity to be presented with, and hopefully solve, a wide variety of problems. Contrary to popular wisdom, I do not wish to be an expert in any field, but to know enough about everything to tackle anything. | ||
|
|
||
| Unfortunately, as data science becomes more mainstream there has been a shift to break up the responsibilities into more specialised roles, such as: | ||
| - Analyst | ||
| - Data engineer | ||
| - Machine learning engineer | ||
| - MLops | ||
|
|
||
| While these distinctions can optimize a particular part of the solution, you lose the nuance that comes with understanding the entire problem space. In reality, the hardest part of a data scientists job is translating the messy real world into a clean data problem that can be solved by any old algorithm. By the time we come to fitting a machine learning model, we have made a whole heap of assumptions/work arounds to simplify the real world problem into a sufficiently straightforward dataset. Yes, algorithms and models are cool, but it is this creative element that I enjoy and the reason I am not a data engineer. | ||
|
|
||
| However, much of this subtlety is often overlooked in favour of a shiny new machine learning technique or optimising for a single metric - ideas that are central to the appeal of Kaggle. I have found that most problems on Kaggle have already been translated into a nice neat package, which just encourages a culture of mindlessly applying the biggest neural network possible. Again, this kind of neural network one-up-man-ship misses out the nuance that makes the problem interesting. | ||
|
|
||
| This lack of subtlety also extends to the data science hiring process, which is severely skewed towards having a set of "hard skills". This heavily incentivizes applicants to weigh their CV down with a heap of jargon and buzzwords, in the hope that it will tick a box in the recruiter's mind. Who can blame them? with 100s of CVs to choose from, they have the privilege of choosing someone who already has the right experience, rather than someone willing and able to learn. | ||
|
|
||
| The softer skills like critical thinking, skepticism and communication are hard to convey on a single page CV or even in a standard "question and answer" interview. I find the best interviews are ones where there is a back and forth discussion centered around one of my past projects. This allows me to talk about the project as a whole, rather than just the fact I used a "Bayesian workflow" as stated on my CV. Crucially, it also gives me confidence that the interviews are on the same wavelength and I can look forward to bouncing ideas off these people in the future. | ||
|
|
||
| ## Data Science is Hard to Describe (but You'll Know it when You See it) | ||
|
|
||
| Part of the problem is that no-one can agree on what the phrase "data science" actually means. Many articles have already described the industry changes in the past decade ([Data science is different now](https://vickiboykis.com/2019/02/13/data-science-is-different-now/), [Hiring and Interviewing Data Scientists](https://ericmjl.github.io/essays-on-data-science/people-skills/hiring/)), but I'll just add two perspectives I've gained: | ||
| - For a someone with a PhD moving into industry, data science represents the same kind of coding/stats based project on business, rather than scientific, data. Through this lens, I care less about the context of the problem and more about being able to solve something in a satisfactory manner. I want to be excited to try new techniques, present ideas in new ways and apply the soft skills I subconsciously absorbed during my PhD | ||
| - For a senior data leader, data science is a chance to change how the business operates and unlock the potential gold mine of information about the customers/product. Crucially, they have to sell this capability to the rest of the business. This means they can often not afford for a 3-6 month research project to use up resources and not be successful | ||
|
|
||
| Both of these views are completely valid, but the difference in expectation can be jarring. | ||
|
|
||
| # How to fix this? | ||
|
|
||
| ## Finding jobs | ||
|
|
||
| Know what you want. This will become obvious with experience but its sometimes useful to reference a framework like the one below | ||
|
|
||
| 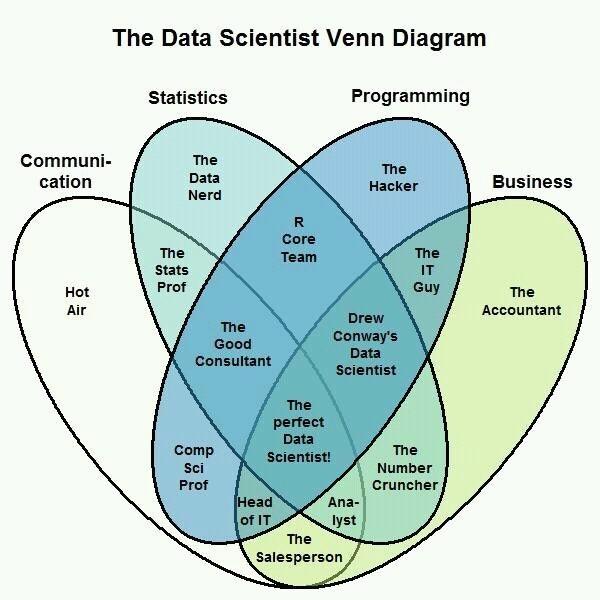 | ||
|
|
||
| Not only does this help you wade through the sea of job adverts, it means you don't have to lie when they ask you "why do you want this job?". | ||
|
|
||
| Unfortunately, the job title alone does not give you enough information. To understand the context of your role in the business you need to ask: "Where on the data science spectrum will I sit?", "Who will I report to?" "and "How well organised is the data?". Questions such as these can be gleaned from a job description, but it is easier to spot these [[Red Flags to Look Out for When Joining a Data Team|red flags]] during the interviews. Over time, one starts to learn the language of recruiters. It then becomes easier to translate phrases like "working with stakeholders to achieve growth targets" into a culture where OKRs must be met at all costs. Often at the expense of deeper, more interesting, projects. | ||
|
|
||
| ## Proving your skills | ||
|
|
||
| A portfolio website, or active GitHub, can be a great way to demonstrate your soft skills/project experience in more detail. Even the act of creating one shows a willingness to learn and the dedication to keep it up to date ([[Why Have a Data Science Portfolio and What It Shows]]). | ||
|
|
||
| Sometimes it is hard to even understand what soft skills you excel at. These things may seem natural to you, but are a strength when compared to others. | ||
|
|
||
| Give an extra level of detail, or intrigue, into the interview to guide the questioning down a path you are an expert in, e.g.: | ||
| - "as I found when sending a balloon to space" | ||
| - "I know about this because of that time I worked on space weather" | ||
| - "I do a similar thing in my note taking app" | ||
|
|
||
| ## During a Project | ||
|
|
||
| Before a project starts, I find it is important to have a "taste" for what kind of project works and what kind of project I am good at. Like any taste, this builds over time by trying new things. Even if it fails, at least you have something to write about. | ||
|
|
||
| Plotting data is never a bad thing. So many of data science's intricacies can spotted by plotting your data and comparing it to your expectations. Are there any bad values? Weird straight lines that shouldn't exist? Any obvious non-linear correlations? All of these questions become immediately obvious once plotted and give you something visual to paste into a slide other than an R squared value. | ||
|
|
||
| Companies need to make money. So it can be very hard to ask a business to "let me think about it". You need to build trust that there will has been progress, and potentially a pay off at the end of the research phase. A one-pager is a good way to convey this information, with the written form allowing you to truly think through the problem and your stakeholders to understand it asynchronously. A roadmap can also help build trust with the stakeholders, and gives them a sense of ownership over the project. See this [article](https://eugeneyan.com/writing/what-i-do-before-a-data-science-project-to-ensure-success/) for more detail. | ||
|
|
||
| # Sources | ||
|
|
||
| Most of the ideas in this blog were absorbed from the sources below: | ||
| - [The Future of Data Science is Past](https://koaning.io/posts/the-future-is-past/) | ||
| - [The profession of solving (the wrong problem)](https://www.youtube.com/watch?v=kYMfE9u-lMo) | ||
| - [Natural Intelligence is All You Need](https://www.youtube.com/watch?v=C9p7suS-NG) | ||
| - [Statistical rethinking](https://youtu.be/FdnMWdICdRs?si=CMqpu_mPa8l7MRmD) | ||
| - [Data science is different now](https://vickiboykis.com/2019/02/13/data-science-is-different-now/) | ||
| - [Hiring data scientists](https://ericmjl.github.io/essays-on-data-science/people-skills/hiring/) | ||
| - [Data science roles](https://eugeneyan.com/writing/data-science-roles/) | ||
| - [Getting a DS job](https://ravinkumar.com/GettingADSJob.html) | ||
| - [Red Flags to Look Out for When Joining a Data Team](https://eugeneyan.com/writing/red-flags/) | ||
| - [Why Have a Data Science Portfolio and What It Shows](https://eugeneyan.com/writing/data-science-portfolio-how-why-what/) |